Appearance
Thread IO Model
Redis is a single-threaded program! This must be remembered.
You may doubt how a high-concurrency middleware like Redis can be single-threaded. Unfortunately, it is single-threaded; your doubts reveal a lack of foundational knowledge. Do not underestimate single-threading. Besides Redis, Node.js and Nginx are also single-threaded, yet they exemplify high-performance servers.
Why is Redis single-threaded and still so fast?
Because all its data resides in memory, all operations are at memory level. Being single-threaded means caution is needed when using Redis commands. For commands with a time complexity of O(n), one must be particularly careful, as they can easily cause Redis to stall.
How does Redis single-threaded handle so many concurrent client connections?
This question stumps many mid to senior programmers, as they are unfamiliar with the term "multiplexing," the select series of event polling APIs, or non-blocking IO.
Non-blocking IO
When we call read/write methods on a socket, they are blocking by default. For example, the read method requires a parameter n, indicating the maximum bytes to read before returning. If no bytes are available, the thread will block until new data arrives or the connection closes. The write method typically doesn't block unless the kernel's write buffer is full, causing it to block until space becomes available.
Non-blocking IO provides a Non_Blocking option on socket objects. When enabled, read/write methods won't block; they read/write whatever is available. The amount read depends on the kernel's allocated read buffer, while the amount written depends on the free space in the write buffer. Both methods inform the program of the actual bytes read/written through their return values.
With non-blocking IO, threads can read/write without blocking, allowing them to perform other tasks immediately.
Event Polling (Multiplexing)
A challenge with non-blocking IO is knowing when to continue reading if a partial read occurs. Similarly, when the write buffer is full, the thread needs notification of when to continue writing.
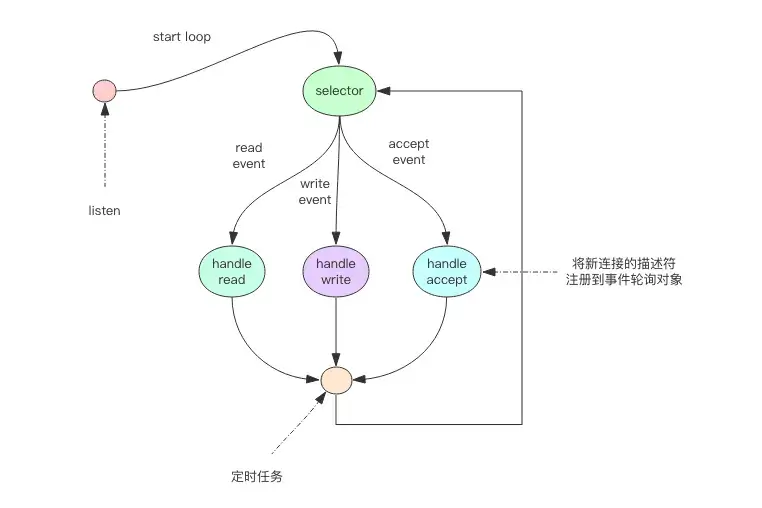
The event polling API solves this problem. The simplest is the select function, which is an API provided by the operating system. It takes lists of read/write descriptors as input and outputs corresponding readable/writable events, with a timeout parameter. If no events arrive, the thread waits in a blocking state for up to the timeout duration. If an event arrives during this time, it returns immediately. If time passes with no events, it also returns immediately. Once events are received, the thread can process them in sequence and continue polling. This forms a loop known as the event loop, with each cycle representing a period.
Each client socket has corresponding read/write file descriptors.
python
read_events, write_events = select(read_fds, write_fds, timeout)
for event in read_events:
handle_read(event.fd)
for event in write_events:
handle_write(event.fd)
handle_others() # Handle other tasks, like scheduled jobsBecause we handle multiple channel descriptor read/write events simultaneously through the select system call, we call such calls multiplexing APIs. Modern operating systems have moved beyond select to epoll (Linux) and kqueue (FreeBSD & macOS) due to select's poor performance with numerous descriptors. While their usage may differ slightly, they are fundamentally similar and can be understood using the above pseudocode logic.
The server socket's read operation refers to calling accept to accept new client connections. Notifications for new connections also come through the read events of the select system call.
The event polling API corresponds to Java's NIO technology.
Java's NIO is not exclusive to Java; other programming languages have similar technologies under different names.
Instruction Queue
Redis associates each client socket with an instruction queue. Client instructions are processed in order via this queue, serving them on a first-come, first-served basis.
Response Queue
Redis also associates a response queue with each client socket. The Redis server uses this queue to reply with the results of commands. If the queue is empty, it indicates the connection is temporarily idle, so there's no need to fetch write events, allowing the current client descriptor to be removed from write_fds. Once data is available in the queue, the descriptor is re-added. This prevents a situation where the select system call returns write events, only to find there's nothing to write, which could spike CPU usage.
Scheduled Tasks
In addition to responding to IO events, the server must handle other tasks, such as scheduled tasks. If a thread blocks on the select system call, scheduled tasks won't execute timely. How does Redis solve this?
Redis records scheduled tasks in a data structure known as a min-heap, where the tasks due for execution are at the top. During each cycle, Redis processes any tasks that are due immediately. After processing, it records the time required for the next soonest task, which becomes the timeout parameter for the select system call. Since Redis knows no other scheduled tasks need processing within the timeout, it can sleep safely for that duration.
Nginx and Node's event handling principles are similar to Redis.