Appearance
Scan
In the routine online maintenance of Redis, there are times when you need to find a list of keys with a specific prefix from thousands of keys in a Redis instance for manual data processing, which may involve modifying their values or deleting keys. This raises the question: how do you find a list of keys that match a specific prefix among a vast number of keys?
Redis provides a simple yet brute-force command, keys, to list all keys that match a specific regular expression pattern.
plaintext
127.0.0.1:6379> set codehole1 a
OK
127.0.0.1:6379> set codehole2 b
OK
127.0.0.1:6379> set codehole3 c
OK
127.0.0.1:6379> set code1hole a
OK
127.0.0.1:6379> set code2hole b
OK
127.0.0.1:6379> set code3hole b
OK
127.0.0.1:6379> keys *
1) "codehole1"
2) "code3hole"
3) "codehole3"
4) "code2hole"
5) "codehole2"
6) "code1hole"
127.0.0.1:6379> keys codehole*
1) "codehole1"
2) "codehole3"
3) "codehole2"
127.0.0.1:6379> keys code*hole
1) "code3hole"
2) "code2hole"
3) "code1hole"This command is very straightforward; you just provide a simple regular expression string. However, it has two significant drawbacks:
- It lacks
offsetandlimitparameters, returning all keys that match the conditions at once. If there are hundreds of thousands of keys that satisfy the condition, the overwhelming flood of strings can be quite distressing. - The
keysalgorithm is a traversal algorithm with a complexity of O(n). If there are tens of millions of keys in the instance, this command can cause Redis service lag, delaying or even timing out other read and write commands to Redis. This is because Redis is a single-threaded program that executes all commands sequentially, meaning other commands must wait until the currentkeyscommand is completed.
How do we address these two significant drawbacks?
To solve this problem, Redis introduced the scan command in version 2.8. Compared to keys, scan has the following features:
- Although its complexity is also O(n), it uses a cursor to perform incremental scanning, which does not block the thread.
- It provides a
limitparameter to control the maximum number of results returned each time; thelimitis merely a hint, and the actual results can vary. - Like
keys, it also offers pattern matching capabilities. - The server does not need to maintain the state of the cursor; the only state of the cursor is the integer returned to the client by
scan. - The returned results may have duplicates, requiring the client to handle deduplication, which is very important.
- If there are data modifications during the traversal, whether the modified data can be traversed is uncertain.
- An empty result for a single return does not mean the traversal is finished; you need to check if the returned cursor value is zero.
Basic Usage of Scan
Before using scan, let’s insert 10,000 data entries into Redis for testing:
python
import redis
client = redis.StrictRedis()
for i in range(10000):
client.set("key%d" % i, i)Now that Redis contains 10,000 data entries, let's find the list of keys starting with key99.
The scan command takes three parameters: the first is the cursor integer value, the second is the key's regular expression pattern, and the third is the traversal limit hint. During the first traversal, the cursor value is 0, and the first integer value returned will be used as the cursor for the next traversal. This continues until the returned cursor value is 0, indicating the end.
plaintext
127.0.0.1:6379> scan 0 match key99* count 1000
1) "13976"
2) 1) "key9911"
2) "key9974"
3) "key9994"
4) "key9910"
5) "key9907"
6) "key9989"
7) "key9971"
8) "key99"
9) "key9966"
10) "key992"
11) "key9903"
12) "key9905"plaintext
127.0.0.1:6379> scan 13976 match key99* count 1000
1) "1996"
2) 1) "key9982"
2) "key9997"
3) "key9963"
4) "key996"
5) "key9912"
6) "key9999"
7) "key9921"
8) "key994"
9) "key9956"
10) "key9919"plaintext
127.0.0.1:6379> scan 1996 match key99* count 1000
1) "12594"
2) 1) "key9939"
2) "key9941"
3) "key9967"
4) "key9938"
5) "key9906"
6) "key999"
7) "key9909"
8) "key9933"
9) "key9992"
......plaintext
127.0.0.1:6379> scan 11687 match key99* count 1000
1) "0"
2) 1) "key9969"
2) "key998"
3) "key9986"
4) "key9968"
5) "key9965"
6) "key9990"
7) "key9915"
8) "key9928"
9) "key9908"
10) "key9929"
11) "key9944"From the above process, you can see that although the provided limit is 1000, the returned results are only around 10. This is because the limit does not restrict the number of returned results; rather, it limits the number of dictionary slots (approximately) that the server scans in one go. If you set the limit to 10, you will find that the returned results are empty, but the cursor value is not zero, indicating that the traversal has not yet finished.
plaintext
127.0.0.1:6379> scan 0 match key99* count 10
1) "3072"
2) (empty list or set)Dictionary Structure
In Redis, all keys are stored in a large dictionary, which has a structure similar to a HashMap in Java, consisting of a one-dimensional array plus a two-dimensional linked list. The size of the first-dimensional array is always (2^n) (where (n \geq 0)), and each expansion of the array doubles its size, i.e., (n++).

The cursor returned by the scan command is the index of the first-dimensional array, which we refer to as a slot. If we ignore dictionary expansions and contractions, we can traverse through the array indices one by one. The limit parameter indicates the number of slots to traverse. The reason the returned results can vary in number is that not all slots will have linked lists; some slots may be empty, while others may have multiple elements linked to them. Each traversal will return all linked list elements connected to the specified number of slots after filtering them through pattern matching.
Scan Traversal Order
The traversal order of the scan command is quite special. It does not traverse from the 0th position of the first-dimensional array to the end; instead, it uses carry-over addition to perform the traversal. This unique method is designed to avoid duplicate and missing slots during dictionary expansion and contraction.
First, let’s illustrate the difference between regular addition and carry-over addition with an animation.
From the animation, we can see that carry-over addition starts from the left and moves the carry to the right, which is the opposite of regular addition. However, both methods will ultimately traverse all slots without duplication.
Dictionary Expansion
Java’s HashMap has the concept of expansion. When the loadFactor reaches a threshold, it needs to allocate a new array that is twice the size and rehash all elements to the new array. Rehashing involves taking the hash value of each element modulo the length of the array. Since the length changes, the slot to which each element is mapped may also change. Because the array length is a power of (2^n), the modulo operation is equivalent to a bitwise AND operation.
plaintext
a mod 8 = a & (8-1) = a & 7
a mod 16 = a & (16-1) = a & 15
a mod 32 = a & (32-1) = a & 31Here, 7, 15, and 31 are referred to as the mask values of the dictionary, and their purpose is to retain the low bits of the hash value, while setting the high bits to 0.
Next, let’s examine the changes in element slots before and after rehashing.
Assuming the current dictionary array length is expanded from 8 to 16, slot 3 (011 in binary) will be rehashed into slots 3 and 11. This means that about half of the elements in that slot will still be in slot 3, while the others will go to slot 11 (the binary for 11 is 1011, which is just 3 with a high bit of 1 added).

In a more abstract way, if the initial slot's binary is xxx, the elements in that slot will be rehashed to 0xxx and 1xxx (xxx + 8). If the dictionary length expands from 16 to 32, the elements in binary slot xxxx will be rehashed to 0xxxx and 1xxxx (xxxx + 16).
Comparison of Traversal Orders Before and After Expansion
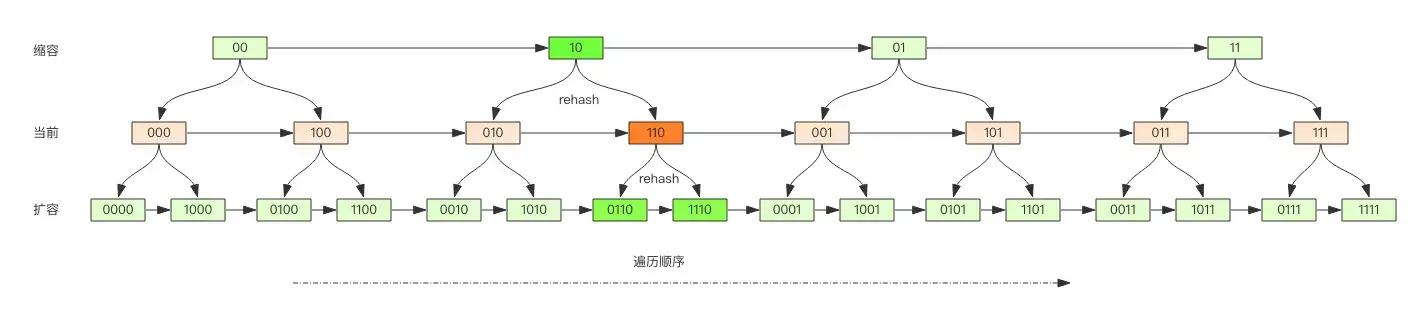
Observing this image, we find that the traversal order using carry-over addition results in rehashed slots being adjacent in the traversal sequence.
Suppose we are about to traverse position 110 (orange). After expansion, all elements in the current slot correspond to new slots 0110 and 1110 (dark green). We can directly continue traversing from slot 0110 since all previous slots have already been traversed, thus avoiding redundant traversals of slots that have already been visited.
Now, consider contraction. If we are about to traverse position 110 (orange), after contraction, all elements in the current slot will correspond to new slot 10 (dark green), effectively removing the highest bit from the slot binary. We can continue traversing from slot 10, as all previous slots have been traversed. However, contraction is slightly different because it may lead to duplicate traversals of elements in slot 010 due to the merging of elements from slots 010 and 110.
Incremental Rehashing
Java’s HashMap moves all elements from the old array to the new one all at once during expansion. If there are a lot of elements in the HashMap, threads may experience delays. To address this, Redis uses incremental rehashing.
Redis retains both the old and new arrays and gradually transfers elements from the old array to the new one during scheduled tasks and subsequent hash operations. This means that accessing a dictionary undergoing rehashing requires accessing both the old and new array structures. If an element is not found in the old array, it must also be searched in the new array.
The scan command also needs to consider this situation; for dictionaries undergoing rehashing, it must scan both old and new slots and merge the results before returning them to the client.
More Scan Commands
The scan command is part of a series of commands that can not only traverse all keys but also scan specified container collections. For example, zscan can traverse elements in a zset collection, hscan can scan elements in a hash dictionary, and sscan can traverse elements in a set collection.
Their underlying principles are similar to scan, as the hash structure is fundamentally a dictionary, and a set is a special kind of hash (with all values pointing to the same element). Zsets also use dictionaries to store their elements, so we won’t elaborate further on this.
Scanning Large Keys
Sometimes, due to improper usage by business personnel, large objects may be formed in Redis instances, such as a large hash or a large zset. Such large objects can cause significant issues during data migration in a Redis cluster. In a clustered environment, if a key is too large, it may cause migration delays. Additionally, if a key is too large and requires expansion, it may request a significantly larger memory block at once, causing lag. Similarly, if this large key is deleted, memory will be reclaimed all at once, which can also lead to lag.
During regular business development, you should try to avoid the creation of large keys.
If you observe large fluctuations in Redis memory, it is highly likely caused by large keys. In this case, you need to identify which specific key is responsible, trace back to the relevant business source, and improve the associated business code design.
So how can we identify large keys?
To avoid causing lag on the live Redis instance, we can use the scan command. For each scanned key, use the type command to obtain the key's type, and then use the corresponding data structure's size or len method to get its size. For each type, retain the top N sizes as the scan results.
This process requires scripting and can be somewhat tedious. However, the Redis official CLI provides scanning functionality that we can use directly.
plaintext
redis-cli -h 127.0.0.1 -p 7001 --bigkeysIf you're concerned that this command will significantly increase Redis operations and cause alerts, you can add a sleep parameter.
plaintext
redis-cli -h 127.0.0.1 -p 7001 --bigkeys -i 0.1The above command will sleep for 0.1 seconds after every 100 scan commands, preventing a dramatic increase in ops, but the scanning duration will be longer.