Appearance
Redis Cluster
RedisCluster is the official clustering solution provided by the author of Redis.
Unlike Codis, it is decentralized; as shown, the cluster consists of three Redis nodes, each responsible for a portion of the cluster's data, which may vary. These nodes are interconnected, forming a peer-to-peer cluster, exchanging cluster information through a special binary protocol.
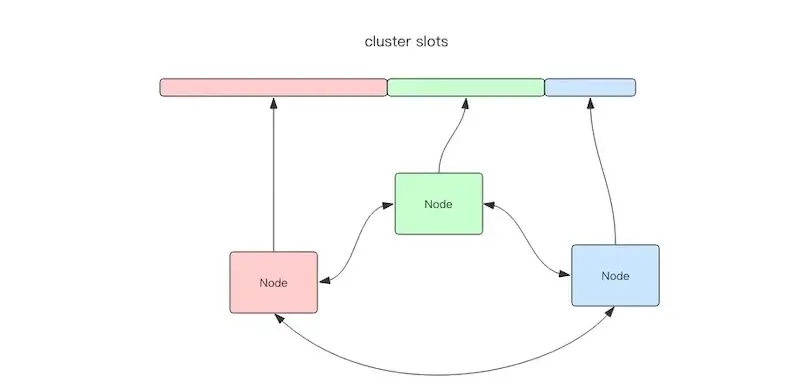
Redis Cluster divides all data into 16,384 slots, a finer granularity than Codis's 1,024 slots, with each node managing a subset of these slots. Slot information is stored in each node, eliminating the need for additional distributed storage for node slot information as seen in Codis.
When a Redis Cluster client connects, it receives the cluster's slot configuration. This allows the client to directly locate the target node when searching for a key. Unlike Codis, which requires a Proxy for node location, RedisCluster allows direct targeting. To efficiently locate the node of a specific key, clients must cache slot information, necessitating a correction mechanism for potential inconsistencies between the client and server.
Additionally, each node in RedisCluster persists cluster configuration information to a configuration file, which must be writable, and manual modifications should be avoided.
Slot Location Algorithm
The cluster uses the CRC16 algorithm to hash key values into an integer, which is then modulo'd by 16,384 to obtain the specific slot.
Cluster also allows users to enforce a key to reside in a specific slot by embedding a tag within the key string, ensuring the key's slot matches the tag's slot.
ruby
def HASH_SLOT(key)
s = key.index "{"
if s
e = key.index "}", s + 1
if e && e != s + 1
key = key[s + 1..e - 1]
end
end
crc16(key) % 16384
endRedirection
When a client sends a command to an incorrect node, the node recognizes that the key's slot does not belong to it and sends a special redirection command to the client, providing the address of the target node.
GET x
-MOVED 3999 127.0.0.1:6381The first parameter, 3999, is the slot number for the key, followed by the target node's address. The "-" indicates an error message.
Upon receiving the MOVED command, the client must immediately correct its local slot mapping. Subsequent keys will use the new slot mapping.
Migration
Redis Cluster offers the redis-trib tool for operations personnel to manually adjust slot allocations, developed in Ruby by combining various native Redis Cluster commands. Codis provides a more user-friendly interface with UI tools for easier migration and automated balancing, while Redis focuses on minimal tooling, leaving additional features to the community.
Migration Process
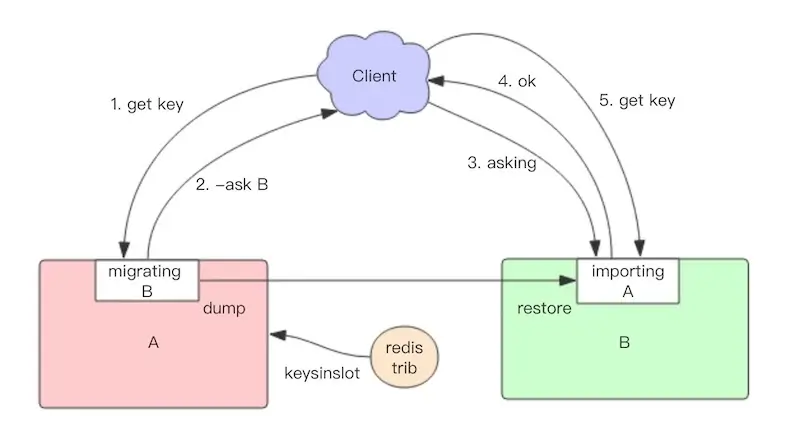
Redis migration occurs slot by slot. When a slot is migrating, it enters a transitional state: "migrating" on the source node and "importing" on the target node, indicating data transfer from source to target.
The migration tool redis-trib first sets up this transitional state on both nodes, retrieves a list of all keys in the source node's slot (using the keysinslot command), and migrates each key. Each key's migration is handled by the source node acting as a "client" to itself, executing the dump command to serialize the content, then sending a restore command to the target node with the serialized content as an argument. The target node deserializes the content into its memory and returns "OK" to the source node, which then deletes the key, completing the migration.
If a network failure occurs midway through migration, the two nodes will remain in the transitional state. When the migration tool reconnects, it will prompt the user to continue.
During migration, if each key's content is small, the migrate command executes quickly and does not impact client access. However, for large key contents, blocking commands may stall both nodes, affecting cluster stability. Hence, business logic should avoid generating large keys in clustered environments.
During migration, client access processes undergo significant changes.
Initially, both the old and new nodes may have some key data. The client attempts to access the old node; if the data exists, it processes normally. If the data is not found, it may be on the new node or nonexistent. The old node, unaware, returns an -ASK targetNodeAddr redirect command. Upon receiving this, the client sends an asking command to the target node, then retries the original operation.
Why is the asking command necessary?
Before migration completion, the slot still technically belongs to the old node. Sending commands to the target node would lead to a -MOVED redirect, creating a loop. The asking command informs the target node to process the next command as its own.
From the process above, it’s clear that migration impacts service efficiency; typically, one TTL can complete a command, but during migration, it may take three TTLs.
Fault Tolerance
Redis Cluster allows setting several replicas for each master node. If a master node fails, the cluster automatically promotes one of its replicas to master. If a master has no replicas, the cluster becomes entirely unavailable. However, Redis provides the cluster-require-full-coverage parameter to allow partial node failures while other nodes continue external access.
Network Fluctuations
In reality, data center networks often face various small issues. Network jitter, for instance, is common, where some connections suddenly become inaccessible and quickly return to normal.
To address this, Redis Cluster offers the cluster-node-timeout option, indicating that a node is deemed failed only after a sustained timeout. Without this option, network jitter can lead to frequent master-slave switching and data replication.
Another option, cluster-slave-validity-factor, scales this timeout to relax fault tolerance. A factor of zero disables tolerance to network jitter, while a factor greater than one serves as a relaxation coefficient for switching.
Possibly Fail (PFAIL) vs. Fail
Due to its decentralized nature, one node's view of another's failure may not be universally recognized. Therefore, the cluster undergoes a consensus process: only when a majority acknowledges a node's failure can the cluster initiate master-slave switching for fault tolerance.
Redis Cluster nodes use a Gossip protocol to broadcast their status and perceptions of the entire cluster. For instance, if a node detects another as failed (PFail), it broadcasts this information to the cluster. If a node counts a sufficient number of failures (PFail Count) to reach a majority, it marks the node as failed (Fail), notifying the cluster to enforce a master-slave switch.
Basic Cluster Usage
The redis-py client does not support Cluster mode. To use Cluster, you must install an additional package that depends on redis-py.
bash
pip install redis-py-clusterNow, let’s look at how to use redis-py-cluster.
python
>>> from rediscluster import StrictRedisCluster
>>> # Requires at least one node for cluster discovery. Multiple nodes are recommended.
>>> startup_nodes = [{"host": "127.0.0.1", "port": "7000"}]
>>> rc = StrictRedisCluster(startup_nodes=startup_nodes, decode_responses=True)
>>> rc.set("foo", "bar")
True
>>> print(rc.get("foo"))
'bar'Cluster is decentralized, consisting of multiple nodes. When constructing a StrictRedisCluster instance, a single node address suffices, with others discoverable through it. However, providing multiple addresses enhances security. If only one address is given, a failure of that node necessitates address switching for continued Cluster access. The second parameter, decode_responses, indicates whether to convert byte arrays in returned results to Unicode.
Using Cluster is very convenient, similar to ordinary redis-py, with only differences in construction methods. However, there are significant differences, such as Cluster not supporting transactions, a slower mget method broken into multiple get commands, and the non-atomic nature of the rename method, which requires data transfer between nodes.
Slot Migration Awareness
How can clients detect slot changes during migration in a Cluster? The client maintains a mapping of slots to nodes and must receive timely updates to correctly direct commands.
Previously, we mentioned two special error commands in the Cluster: moved and asking.
The moved command corrects slot errors. If a command is sent to the wrong node, it responds with a moved command and the target node's address, prompting the client to access the correct node. The client refreshes its slot mapping table and retries the command, redirecting all subsequent commands for that slot to the target node.
The asking command differs; it temporarily corrects slot information. If a slot is migrating, commands first go to the old node. If data exists there, the result is returned. If not, it may genuinely be missing or on the target node. The old node notifies the client to attempt fetching data from the new node, returning an asking error with the target node's address. The client goes to the target node to retry without refreshing the slot mapping, as it only temporarily corrects the information.
Retry Twice
Both the moved and asking commands are retry directives, causing the client to retry once more. Have you considered whether a client might actually retry twice? This can occur when a command is sent to the wrong node, which responds with a moved error, instructing the client to retry at another node. If, at that moment, a migration operation is underway, the client may then receive an asking command, prompting a second retry.
Multiple Retries
In certain special cases, clients could even retry multiple times. Think creatively about scenarios that might lead to such behavior.
Given the possibility of multiple retries, client source code typically includes a loop during command execution, setting a maximum retry count. Both Java and Python allow this parameter, but with different values. If the retry count exceeds this limit, an exception is thrown to the business layer.
Cluster Change Awareness
When server nodes change, clients should receive immediate notifications to refresh their node relationship tables. How are these notifications communicated? There are two scenarios:
- If the target node fails, the client raises a
ConnectionErrorand randomly retries another node, which may then return amovederror with the new address for the target slot. - If operations personnel manually change cluster information, switching the master to another node and removing the old master, commands sent to the old node will return a
ClusterDownerror, indicating that the current cluster is unavailable (the node is isolated). The client then closes all connections, clears the slot mapping table, and raises an error. When the next command arrives, it attempts to reinitialize node information.