Appearance
Pipeline
Most students have long had a misunderstanding about Redis pipelines. They believe that this is a special technology provided by the Redis server that can accelerate Redis access efficiency. However, in reality, Redis pipelines are not a technology directly offered by the Redis server; this technology is essentially provided by the client and has no direct relation to the server. Below, we will delve deeper into this topic.
Message Interaction in Redis
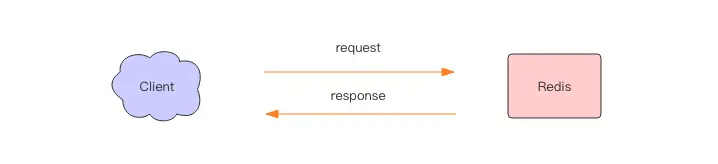
When we use a client to perform an operation on Redis, as shown in the figure below, the client sends a request to the server, and after processing, the server replies to the client. This takes the time of one round-trip network packet.
If multiple commands are executed consecutively, it will take the time of multiple round-trip network packets, as shown in the figure below.
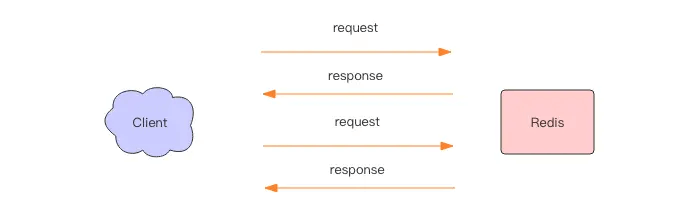
Returning to the client code level, the client has gone through four operations—write, read, write, read—to fully execute two commands.

Now, if we change the order of reads and writes to write-write-read-read, these two commands can also complete normally.

Two consecutive write operations and two consecutive read operations will only take the time of one round-trip network packet, as if the consecutive write operations and the consecutive read operations were merged.
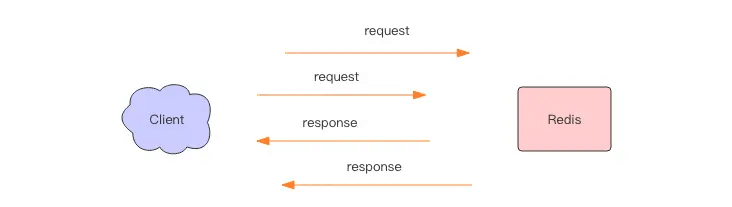
This is the essence of pipeline operations; the server treats them in the same way—receiving a message, executing a message, and replying to a message in the normal process. By changing the order of commands in the pipeline, the client can greatly save I/O time. The more commands in the pipeline, the better the effect.
Pipeline Stress Testing
Next, let's practice the power of pipelines.
Redis comes with a stress testing tool called redis-benchmark, which can be used to conduct pipeline tests.
First, we conduct a stress test on a normal SET command, achieving approximately 50,000 requests per second (QPS).
bash
redis-benchmark -t set -q
SET: 51975.05 requests per secondWe add the pipeline option -P, which indicates the number of parallel requests within a single pipeline. With P=2, the QPS reaches 90,000.
bash
redis-benchmark -t set -P 2 -q
SET: 91240.88 requests per secondLooking at P=3, the QPS reaches 100,000.
bash
SET: 102354.15 requests per secondHowever, if we continue to increase the P parameter, we find that the QPS can no longer increase. Why is this?
Because the CPU processing capacity has reached its limit; Redis’s single-threaded CPU has already peaked at 100%, so it cannot be increased further.
Deep Understanding of the Essence of Pipelines
Next, we will analyze the process of a request interaction in depth. The real situation is quite complex, as it passes through the network protocol stack, which requires going into the kernel.
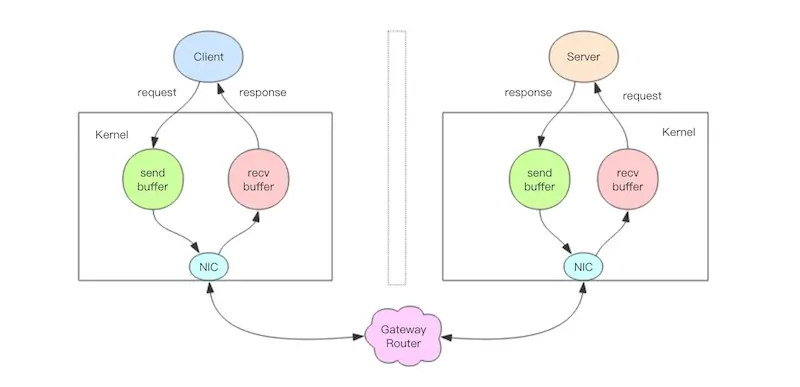
The above diagram illustrates a complete request interaction flowchart. Let me describe it in detail:
- The client process calls
writeto send a message to the operating system kernel, which allocates a send buffer for the socket. - The client operating system kernel sends the contents of the send buffer to the network card, and the network card hardware routes the data to the server's network card.
- The server operating system kernel places the data from the network card into the receive buffer allocated for the socket.
- The server process calls
readto retrieve the message from the receive buffer for processing. - The server process calls
writeto send the response message to the send buffer allocated for the socket in the kernel. - The server operating system kernel sends the contents of the send buffer to the network card, and the network card hardware routes the data to the client's network card.
- The client operating system kernel places the data from the network card into the receive buffer allocated for the socket.
- The client process calls
readto retrieve the message from the receive buffer for processing.
End.
Steps 5 and 14 are the same, but in opposite directions—one is a request, and the other is a response.
We initially thought that the write operation had to wait for the other party to receive the message before returning, but that is not the case. The write operation is only responsible for writing data to the local operating system kernel's send buffer and then returns. The remaining task is left to the operating system kernel to asynchronously send the data to the target machine. However, if the send buffer is full, it needs to wait for space to become available, which is the actual time cost of the write operation.
We initially thought the read operation pulled data from the target machine, but that is not the case either. The read operation is only responsible for retrieving data from the local operating system kernel's receive buffer. If the buffer is empty, it needs to wait for data to arrive, which is the actual time cost of the read operation.
Therefore, for a simple request like value = redis.get(key), the write operation almost incurs no time cost, as it directly writes to the send buffer and returns. The read operation is relatively time-consuming, as it has to wait for the message to travel through the network routing to the target machine, process the response message, and return it to the current kernel's read buffer. This is the true overhead of a network round trip.
For pipelines, however, consecutive write operations incur almost no time cost. The first read operation will wait for one round-trip overhead, and then all response messages will be sent back to the kernel's read buffer, allowing subsequent read operations to immediately retrieve results from the buffer.
Conclusion
This is the essence of pipelines: they are not a feature of the server but a significant performance improvement achieved by the client through changing the order of reads and writes.