Appearance
Codis
In high-concurrency big data scenarios, a single Redis instance often proves inadequate. This inadequacy first manifests in memory limits; a single Redis instance shouldn't have excessive memory, as large RDB files can lead to extended full synchronization times during master-slave replication, and prolonged data loading times during instance recovery—especially in cloud environments with limited memory. Additionally, CPU utilization suffers, as a single Redis instance can only leverage one core, putting immense pressure on that core for managing vast amounts of data.
The need for high concurrency in big data environments has led to the development of Redis clustering solutions, which combine multiple small-memory Redis instances and aggregate CPU capabilities across multiple machines for large data storage and high-concurrency read/write operations.
Codis is one such Redis clustering solution, developed and open-sourced by a team from China, specifically from the former Wandoujia middleware team. Unlike many domestic open-source projects, Codis is highly reliable. With the technological foundation provided by Codis, the project leader Liu Qi later developed TiDB, a distributed database created by Chinese developers.
Years passed between Redis's widespread popularity and the common use of RedisCluster, and Codis emerged to fill this market gap. Large companies have clear online expansion needs for Redis, but suitable middleware solutions were lacking.
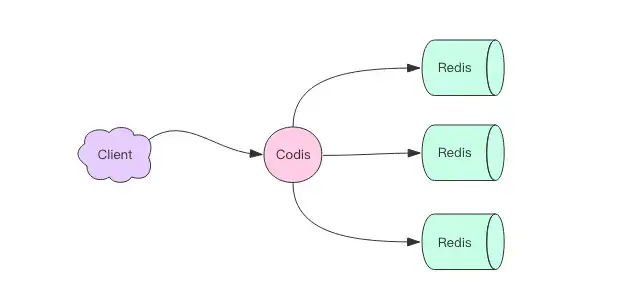
Codis is a proxy middleware developed in Go, using the Redis protocol to provide services. When a client sends commands to Codis, it forwards those commands to the underlying Redis instances for execution and returns the results to the client.
All Redis instances connected to Codis form a Redis cluster. When cluster space is insufficient, new Redis instances can be dynamically added to meet expansion needs. The client interaction with Codis is nearly indistinguishable from interaction with Redis, allowing the use of the same client SDK without any modifications.
Since Codis is stateless, it functions purely as a forwarding proxy, meaning multiple Codis instances can be started for client use, and each Codis node is equal. Given that a single Codis proxy can handle a limited QPS, starting multiple proxies significantly increases overall QPS and provides disaster recovery; if one Codis proxy fails, others can continue to serve.
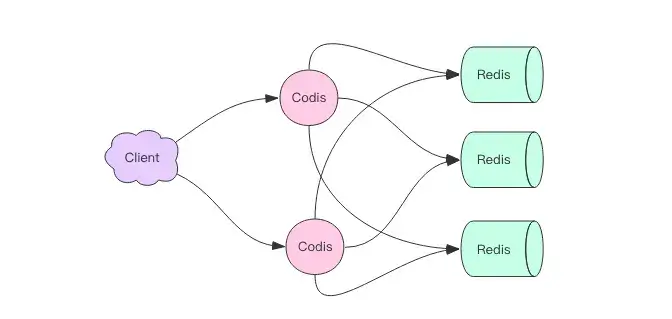
Codis Sharding Principle
Codis must forward specific keys to particular Redis instances. It manages this mapping by dividing all keys into 1024 slots by default. It first computes the CRC32 hash of the client-provided key, then takes the modulus of this hash with 1024 to determine the corresponding slot.
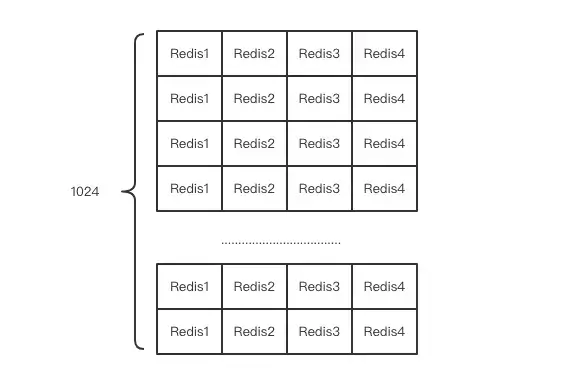
Each slot uniquely maps to one of the Redis instances, and Codis maintains this mapping in memory. Once the slot for a given key is known, it can easily forward commands to the appropriate Redis instance.
plaintext
hash = crc32(command.key)
slot_index = hash % 1024
redis = slots[slot_index].redis
redis.do(command)The default number of slots is 1024 but can be configured to larger values, such as 2048 or 4096, for clusters with more nodes.
How do different Codis instances synchronize slot relationships? If the mapping were only stored in memory, synchronization would not be possible. Thus, Codis requires a distributed configuration storage database to persist slot relationships. Initially, Codis used ZooKeeper but later added support for etcd.
Codis stores slot relationships in ZooKeeper and provides a Dashboard for monitoring and modifying these mappings. When changes occur, Codis Proxy listens for updates and synchronizes the slot relationships, ensuring that multiple Codis Proxies share the same configuration.
Expansion
Initially, Codis might have just one Redis instance, with all 1024 slots pointing to it. When that instance runs out of memory, another Redis instance can be added, requiring an adjustment in the slot mapping to allocate half of the slots to the new node. This necessitates migrating all keys corresponding to those slots to the new Redis instance.
How does Codis identify all keys for a specific slot? Codis modifies Redis to add a SLOTSSCAN command that traverses all keys under a specified slot. Codis uses SLOTSSCAN to find all keys for migration and moves each key to the new Redis node one by one.
During migration, Codis continues to receive requests for the slots being migrated. Because data exists in both old and new slots, how does Codis decide where to forward requests? Codis cannot determine the current location of the key during migration, so it adopts a different approach. When Codis receives a request for a key in a migrating slot, it immediately forces the migration of that specific key before forwarding the request to the new Redis instance.
plaintext
slot_index = crc32(command.key) % 1024
if slot_index in migrating_slots:
do_migrate_key(command.key) # Force migration
redis = slots[slot_index].new_redis
else:
redis = slots[slot_index].redis
redis.do(command)We know that all Scan commands supported by Redis are subject to duplication; the same is true for Codis's custom SLOTSSCAN. However, this does not impact migration, as once a key is migrated, it is completely deleted from the old instance, preventing it from being scanned again.
Automatic Balancing
Adding new Redis instances requires manual balancing of slots, which can be cumbersome. Therefore, Codis provides an automatic balancing feature. During times of low activity, it monitors the number of slots assigned to each Redis instance and automatically migrates slots if imbalances are detected.
Cost of Codis
While Codis enhances Redis scalability, it also sacrifices some features. Because all keys are distributed across different Redis instances, transactions cannot be supported, as transactions can only be completed within a single Redis instance. Similarly, the rename operation is risky; if two keys exist on different Redis instances, the operation cannot be completed correctly. Codis's official documentation lists commands that are unsupported.
To support scalability, the value of individual keys should not be excessively large, as key migration is the minimum unit. For a hash structure, hgetall is used to retrieve all content at once, and hmset is used to place it on another node. If there are too many key-value pairs within a hash, it may cause migration delays. The official recommendation is to keep the total byte capacity of a single collection structure below 1 MB. For storing social relationship data, such as fan lists, consider using sharded storage for a practical trade-off.
Codis introduces a proxy layer, resulting in greater network overhead compared to a single Redis instance, as data packets traverse an additional network node. The overall performance may decline, but this performance loss is not significant and can be mitigated by increasing the number of proxies.
Codis's configuration center uses ZooKeeper, which adds operational costs for maintaining ZooKeeper. However, most internet companies already have ZooKeeper clusters, making it feasible to utilize existing resources.
Advantages of Codis
Codis simplifies the design compared to the official Redis Cluster, as it delegates distributed concerns to third-party tools like ZooKeeper and etcd, avoiding the complexities of distributed consistency code maintenance. In contrast, Redis Cluster has a complex internal implementation, using a mix of Raft and Gossip protocols and requiring numerous tunable configuration parameters. When issues arise in the cluster, maintenance personnel often struggle to find solutions.
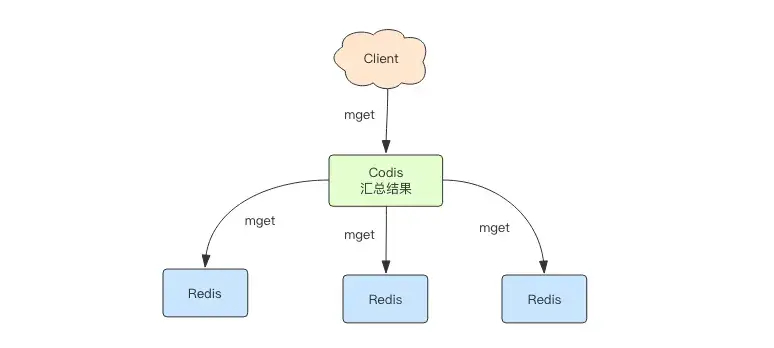
MGET Operation Process
The mget command retrieves values for multiple keys that may be distributed across various Redis instances. Codis's strategy involves grouping keys by their assigned instances, sequentially calling the mget method for each instance, and aggregating the results before returning them to the client.
Architectural Evolution
As an unofficial Redis clustering solution, Codis's architecture has evolved continuously in recent years. It must keep pace with changes in official Redis while enhancing its competitiveness by adding user-friendly features that official Redis lacks, such as a robust Dashboard for cluster management.
Challenges of Codis
Codis, not being an official Redis project, faces a tumultuous fate, often having to follow the lead of official Redis developments. When official Redis introduces new features that Codis lacks, there is a fear of being left behind in the market, necessitating real-time updates.
Due to this lag, Codis typically takes time to adopt the latest functionalities introduced by official Redis. For instance, Redis has advanced to version 4.0 with support for modular plugins, while Codis has not yet offered a solution.
As Redis Cluster becomes more prevalent in the industry, Codis's ability to maintain competitiveness is in question. Codis differentiates itself primarily through tools rather than core functionality, which contrasts sharply with the official route that prioritizes core enhancements while relegating tool development to third parties.
Codis Backend Management
The backend management interface is user-friendly, built with the latest Bootstrap front-end framework. It features real-time QPS fluctuation graphs and supports server cluster management functions, including group addition, node addition, and automatic balancing. Users can also view the status of all slots and see which Redis instance each slot is assigned to.
Reflection & Assignment
Readers are encouraged to attempt building a Codis cluster themselves. Use a Python or Java client to experience standard Redis commands within the Codis cluster.