Appearance
Master-Slave Replication
Many enterprises may not utilize Redis clustering, but most implement master-slave replication. With master-slave setups, when the master fails, operations can promote a slave to take over, allowing services to continue. Without this, the master would need to undergo data recovery and restart, potentially causing significant downtime and impacting online business continuity.
CAP Theorem
Before diving into Redis's master-slave replication, let’s first understand the foundational theory of modern distributed systems—CAP theorem.
- C - Consistency
- A - Availability
- P - Partition Tolerance
Distributed system nodes are typically isolated across different machines, which means there is an inherent risk of network partitions.
During a network partition, two distributed nodes cannot communicate. Any modification made to one node will not synchronize with the other, leading to a lack of data consistency. The only way to ensure consistency is to sacrifice availability, pausing the service on distributed nodes and preventing data modifications until the network issue is resolved.
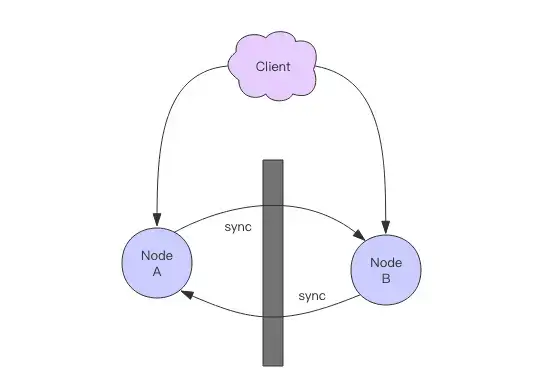
In summary, the CAP theorem states that during a network partition, you cannot achieve both consistency and availability.
Eventual Consistency
Redis uses asynchronous replication, meaning that a distributed Redis system does not meet strict consistency requirements. When a client modifies data on the master node, it returns immediately. Even if a network partition occurs, the master can continue to provide write services, thereby ensuring availability.
Redis guarantees eventual consistency. The slave nodes strive to catch up to the master, and eventually, the states of the slave nodes will align with that of the master. If a network partition occurs, data inconsistencies may arise, but once the network is restored, the slaves will use various strategies to catch up and maintain consistency with the master.
Master-Slave Synchronization
Redis supports both master-slave synchronization and slave-slave synchronization. The latter was added in later versions of Redis to reduce the synchronization burden on the master. For clarity, we will refer to it as master-slave synchronization.
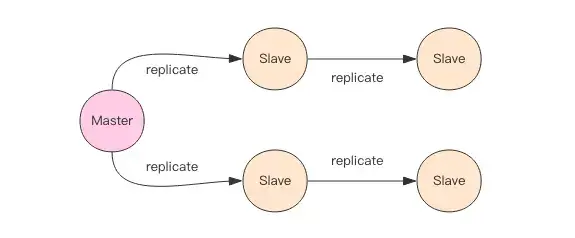
Incremental Synchronization
Redis synchronizes the command stream, where the master records commands that modify its state in a local memory buffer. It asynchronously sends the contents of this buffer to the slave nodes. The slaves execute these commands to reach the same state as the master, while also sending feedback on their synchronization status (offset).
Since the memory buffer is limited, the master cannot retain all commands indefinitely. The replication memory buffer is a fixed-length circular array; when it becomes full, it starts overwriting the oldest commands.

If network conditions worsen and a slave cannot sync for a while, the commands in the buffer may get overwritten. In such cases, a more complex synchronization mechanism—snapshot synchronization—becomes necessary.
Snapshot Synchronization
Snapshot synchronization is resource-intensive. It requires the master to perform a bgsave, creating a snapshot of the current in-memory data, which is then sent to the slave. The slave clears its memory and loads the snapshot data before notifying the master to continue incremental synchronization.
During snapshot synchronization, the master's replication buffer continues to move forward. If the snapshot takes too long or the buffer is too small, incremental commands may be overwritten, resulting in a need for another snapshot synchronization—potentially creating a cycle of snapshot synchronizations.
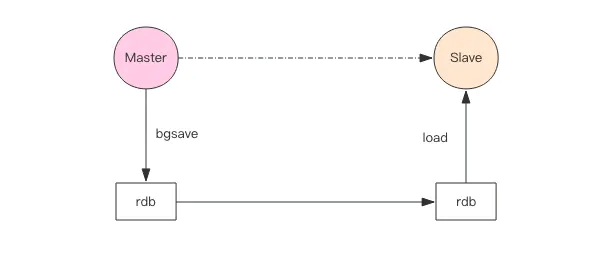
Thus, it's crucial to configure an appropriate buffer size to avoid this issue.
Adding Slave Nodes
When a slave first joins the cluster, it must complete a snapshot synchronization before continuing with incremental synchronization.
Diskless Replication
Snapshot synchronization involves heavy file I/O operations, particularly on non-SSD disks, which can significantly impact the system's load. If a snapshot occurs during an AOF fsync operation, it can delay fsync, severely affecting the master’s service efficiency.
From Redis version 2.8.18 onward, diskless replication was introduced. In this approach, the master sends the snapshot content directly to the slave via a socket. The master traverses its memory and serializes the data, sending it to the slave, which stores it before performing a complete load.
WAIT Command
Redis replication is asynchronous, but the WAIT command allows for a transition to synchronous replication, ensuring stronger consistency (not strict). The WAIT command was introduced in Redis 3.0.
shell
> set key value
OK
> wait 1 0
(integer) 1The WAIT command takes two parameters: the number of slaves (N) to wait for and the time (t) in milliseconds. It ensures that all write operations before the WAIT command synchronize with (N) slaves, waiting a maximum of (t) milliseconds. If (t=0), it waits indefinitely until synchronization is complete.
If a network partition occurs and (t=0), the WAIT command will block indefinitely, causing the Redis server to lose availability.
Summary
Master-slave replication is the foundation of Redis's distributed architecture. High availability in Redis relies on master-slave replication. In subsequent chapters, we will discuss Redis's clustering modes, which all depend on the replication concepts discussed here.
While replication is crucial for persistent data safety, if Redis is only used as a cache, similar to Memcached, you may not need slaves for backup. If a slave fails, a simple restart may suffice. However, if you use Redis's persistence features, it’s vital to take master-slave replication seriously, as it is essential for data safety.