Appearance
Retrieval Part 1
Today, we finally arrive at the last step of building a RAG (Retrieval-Augmented Generation) system—retrieval.
In the previous sections, we discussed VectorStore, which includes several vector-based retrieval methods like search, similarity_search, and max_marginal_relevance_search. However, in real-world development, simply querying the vector database with a question to get the top-k results, and then feeding those results along with the question into an LLM (Large Language Model), may not yield the best outcomes.
There are several reasons for this. For example, the way the question is phrased might not retrieve highly relevant documents from the vector database. Additionally, if the document splitting resulted in blocks that are too large or too small, the retrieved results may lack precision. Furthermore, due to some limitations and characteristics of LLMs, directly feeding the retrieved documents to the model might not produce satisfactory results.
Thus, the process of retrieving relevant documents from the vector database and deciding which documents should ultimately be passed to the LLM involves various considerations. This process entails a range of retrieval strategies, each of which may be suitable in different scenarios. In LangChain, retrieval is treated as a separate module with a series of retrievers designed based on different retrieval strategies.
Compared to VectorStore, a Retriever does not handle vector storage but focuses on how to query document data from the vector database, optimize the processing of document data, and return the final list of documents to be fed into the LLM.
Today, we will first learn about the framework design of retrievers in LangChain, followed by an introduction to some of the retrievers available in LangChain, along with the retrieval strategy principles behind them.
Since there are many types of retrievers, and these strategies are essential for building high-recall RAG applications, we will introduce them over two lessons. Today, we will cover a portion of them.
Retriever Framework Design
To allow for seamless replacement of various retrievers with different strategies, LangChain adopts an abstract interface plus concrete implementation design pattern for retrievers. It first abstracts a base class, BaseRetriever, and defines relevant interfaces, while the actual logic is implemented by each specific class.
Moreover, retrievers are used as components in the LLM chain. Therefore, a retriever is also a Runnable object.
So, let's start with the BaseRetriever.invoke() method to understand the execution flow of a retriever:
python
class BaseRetriever(RunnableSerializable[RetrieverInput, RetrieverOutput], ABC):
def invoke(self, input: str, ...) -> List[Document]:
...
return self.get_relevant_documents(
input,
...
)
def get_relevant_documents(...) -> List[Document]:
run_manager = callback_manager.on_retriever_start(...)
...
result = self._get_relevant_documents(...)
...
run_manager.on_retriever_end(result)
return result
@abstractmethod
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:From the code above, we can see that the invocation path for the retriever is: invoke -> get_relevant_documents -> _get_relevant_documents. In this sequence, get_relevant_documents registers callback events before and after the retrieval, while the actual retrieval logic is implemented in _get_relevant_documents, which is a method that each specific retriever needs to implement.
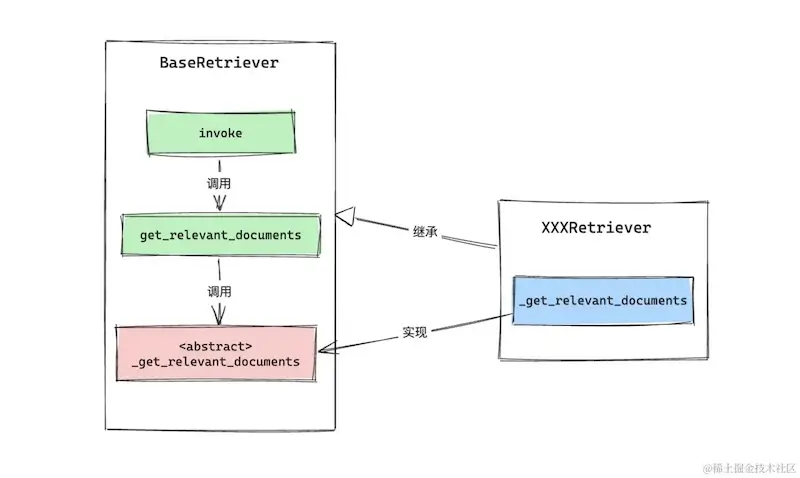
LangChain's design allows different retrievers to customize the retrieval process by implementing this abstract method. This modular approach facilitates experimentation with various retrieval strategies to find the optimal solution for different RAG applications.
VectorStoreRetriever
VectorStoreRetriever is a retriever based on the VectorStore implementation, created using the VectorStore.as_retriever method.
python
class VectorStore(ABC):
def as_retriever(self, **kwargs: Any) -> VectorStoreRetriever:
...
return VectorStoreRetriever(vectorstore=self, **kwargs, ...)VectorStoreRetriever is a lightweight retrieval wrapper for VectorStore. In the as_retriever method, the VectorStore instance is passed as an argument to create a VectorStoreRetriever object. In VectorStoreRetriever._get_relevant_documents, the search method implemented by VectorStore is used to query the text in the vector store.
python
class VectorStoreRetriever(BaseRetriever):
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
# Use semantic similarity search
if self.search_type == "similarity":
docs = self.vectorstore.similarity_search(query, **self.search_kwargs)
# Limit similarity score search
elif self.search_type == "similarity_score_threshold":
docs_and_similarities = (
self.vectorstore.similarity_search_with_relevance_scores(
query, **self.search_kwargs
)
)
docs = [doc for doc, _ in docs_and_similarities]
# Maximum marginal relevance search
elif self.search_type == "mmr":
docs = self.vectorstore.max_marginal_relevance_search(
query, **self.search_kwargs
)
else:
raise ValueError(f"search_type of {self.search_type} not allowed.")
return docsIn VectorStoreRetriever, three different search methods are supported: similarity, similarity_score_threshold, and mmr (these search types can be passed as arguments in VectorStore.as_retriever).
Next, let's illustrate the differences between these search methods with an example.
Before we start, let's do some preparation:
python
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
texts = [
"My dog is mostly black, but its tail is white. It especially loves to go out and play.",
"My dog is all black except for its tail, which is white. It often likes to run outside.",
"My cat is entirely black and also loves going out.",
"Summer is perfect for swimming."
]
vector_store = Chroma.from_texts(texts, embedding=OpenAIEmbeddings())
question = "Can you briefly describe my dog?"We prepared four sentences, vectorized them, and stored them in Chroma. We also prepared a question.
Semantic Similarity Search (similarity)
Now, let's directly use similarity search to find the top 3 most relevant answers from Chroma:
python
retriever = vector_store.as_retriever(search_type="similarity", search_kwargs={"k": 3})
print(retriever.get_relevant_documents(question))Output:
plaintext
[Document(page_content='My dog is mostly black, but its tail is white. It especially loves to go out and play.'),
Document(page_content='My dog is all black except for its tail, which is white. It often likes to run outside.'),
Document(page_content='My cat is entirely black and also loves going out.')]As we can see, because we specified returning 3 results, even though the relevance of sentence 3 ("My cat is entirely black and also loves going out") is relatively low, it is still returned.
Similarity Score Threshold
In semantic search, the algorithm analyzes the similarity between two texts and provides a score between 0 and 1. The closer the score is to 1, the more similar the texts are. Therefore, we can set a threshold to determine the relevance of the search results, such that only documents with a similarity score greater than the threshold will be returned.
In VectorStoreRetriever, this can be achieved by specifying search_type = "similarity_score_threshold" and setting the threshold using search_kwargs.score_threshold.
Let's look at the specific effect:
python
retriever = vector_store.as_retriever(search_type="similarity_score_threshold", search_kwargs={"k": 3, "score_threshold": 0.78})
print(retriever.get_relevant_documents(question))Output:
plaintext
[Document(page_content='My dog is mostly black, but its tail is white. It especially loves to go out and play.'),
Document(page_content='My dog is all black except for its tail, which is white. It often likes to run outside.')]The score_threshold acts as a filter, eliminating results with lower similarity after the semantic similarity search is completed.
Maximum Marginal Relevance Search (MMR)
In the above examples, sentences 1 and 2 are very similar, so both are returned. However, this can be problematic, as these two sentences have identical semantic content, making it sufficient to return just one.
Maximum Marginal Relevance is an algorithm used to improve the relevance of search results. When evaluating a document, it not only calculates the relevance between the document and the query but also considers the similarity with documents already in the selected list. This prevents overly similar content in the results, ensuring diversity and comprehensiveness.
Therefore, when there is too much duplicate content in the document list, we can use the MMR algorithm to avoid redundant results and enhance the quality of the search.
python
retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": 2})
print(retriever.get_relevant_documents(question))Output:
plaintext
[Document(page_content='My dog is mostly black, but its tail is white. It especially loves to go out and play.'),
Document(page_content='Summer is perfect for swimming.')]Here, only sentence 1 is returned, not sentence 2. Additionally, even though sentence 4 has a lower relevance score compared to sentence 3, the MMR algorithm selected sentence 4 to increase the diversity of the results.
MultiQueryRetriever
Distance-based vector database retrieval methods heavily rely on the way the user formulates queries. For instance, a user might want to find information about "artificial intelligence" but use different terms like "AI," "machine intelligence," or "intelligent systems." In such cases, vector retrieval may not accurately recognize the semantic associations between these terms, leading to incomplete search results.
If a single query cannot cover all the documents, multiple queries from different perspectives might solve the issue. MultiQueryRetriever addresses this by generating several similar queries using a language model (LLM) from different angles based on the original user question. It then performs vector retrieval for each generated query, producing a set of documents for each. The combined document sets are deduplicated to form the final query result, providing a more comprehensive result set.
When initializing MultiQueryRetriever, a retriever instance must be passed in for actual retrieval. Think of MultiQueryRetriever as a wrapper or enhancement of other retrievers.
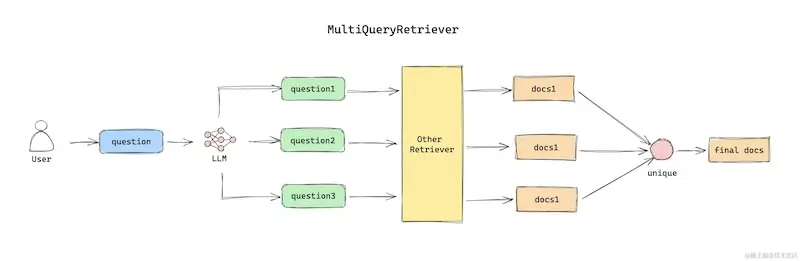
Prompt Template for Generating Multiple Questions
plaintext
template=
"""
You are an AI language model assistant. Your task is
to generate 3 different versions of the given user
question to retrieve relevant documents from a vector database.
By generating multiple perspectives on the user question,
your goal is to help the user overcome some of the limitations
of distance-based similarity search. Provide these alternative
questions separated by newlines. Original question: {question}
"""Translation:
You are an AI language model assistant. Your task is to generate three different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some limitations of distance-based similarity search. Provide these alternative questions separated by newlines. Original question: {question}.
Example of Using MultiQueryRetriever
We will use the VectorStoreRetriever from the previous section as the underlying retriever and demonstrate the usage of MultiQueryRetriever:
python
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
texts = [...]
vector_store = Chroma.from_texts(texts, embedding=OpenAIEmbeddings())
vector_store_retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": 2})
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=vector_store_retriever, llm=ChatOpenAI()
)We can observe the generated queries by setting the logger's print level:
python
import logging
logging.basicConfig()
# Make sure not to misspell the logger name below
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
print(multi_query_retriever.get_relevant_documents("Can you briefly describe my dog?"))Output (example):
plaintext
INFO:langchain.retrievers.multi_query:Generated queries:
['1. What are the characteristics of my dog?', '2. What is the breed of my dog?', '3. What is the temperament of my dog?']
...As shown, the LLM generated several questions from different perspectives.
SelfQueryRetriever
Previously we mentioned that the Document object includes not only the page_content attribute to store the content but also a metadata attribute for recording metadata information. When storing documents in a vector database, these metadata details are stored along with the document content.
python
class VectorStore(ABC):
@classmethod
@abstractmethod
def from_texts(
cls: Type[VST],
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> VST:When querying, most vector databases support filtering by metadata before performing semantic search based on the query. This can significantly reduce the search scope, speed up retrieval, and improve accuracy.
For example, if we load two files, A.pdf and B.pdf, and know that the answer will only appear in A.pdf, we can use a filter such as where source = "A.pdf" during the search to avoid scanning content from B.pdf.
SelfQueryRetriever follows this approach, utilizing an LLM to extract potential metadata from the user's query, forming a filter applied during the search.
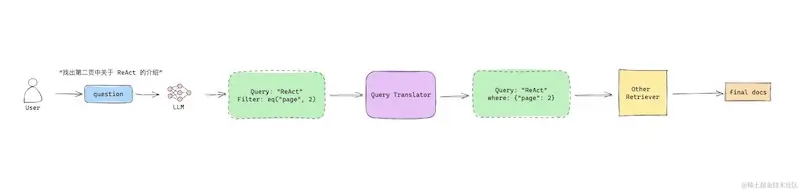
Workflow Overview
(Workflow diagram: image.png)
Different vector databases have varying filter syntax, so a Query Translator is needed to convert filter conditions into the appropriate format for the vector database.
The prompt used to extract metadata with LLM is lengthy, and further details can be found in the documentation. The DEFAULT_SCHEMA serves as the template content.
Using SelfQueryRetriever
Let's demonstrate the use of SelfQueryRetriever with a PDF paper on ReAct. First, we will load the document using PyPDFLoader and store it in the Chroma database.
python
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
loader = PyPDFLoader("ReAct.pdf")
pages = loader.load()
Chroma.from_documents(documents=pages, embedding=OpenAIEmbeddings(), persist_directory="./chroma_db")After loading, we can avoid repeating the process every time by using the following approach:
python
vectorstore = Chroma(persist_directory="./chroma_db", embedding_function=OpenAIEmbeddings())When creating a SelfQueryRetriever, we first need to declare a list of metadata fields, informing the LLM which metadata can be extracted from the query for filtering.
For this example, the Document has two metadata fields: page and source.
plaintext
[Document(page_content="xxx", metadata={'page': 1, 'source': 'ReAct.pdf'})]We can create the following list:
python
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info = [
AttributeInfo(
name="page",
description="The page number of the document.",
type="integer",
),
AttributeInfo(
name="source",
description="The source of the document.",
type="string"
)
]Here, name represents the field name, description describes the field, and type specifies the field type.
Initializing SelfQueryRetriever
Next, we use SelfQueryRetriever.from_llm to initialize the retriever.
python
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import ChatOpenAI
# Description of the document content
document_content_description = "SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS"
self_query_retriever = SelfQueryRetriever.from_llm(
ChatOpenAI(),
vectorstore,
document_content_description,
metadata_field_info,
verbose=True
)
import logging
logging.basicConfig()
# Ensure the logger name is correct
logging.getLogger("langchain.retrievers.self_query").setLevel(logging.INFO)Apart from the metadata_field_info list, the from_llm method requires an LLM instance for extracting metadata from the query, the vectorstore for the final vector database query, and document_content_description, which describes the document content (in this case, the paper's title). Setting verbose=True enables structured query and filter condition logging.
Example Query
Suppose we want to query information about ReAct from page 2. We can pass the question to get_relevant_documents to see the results:
python
print(self_query_retriever.get_relevant_documents("I want to query something about ReAct in page 2"))Output:
plaintext
INFO:langchain.retrievers.self_query.base:Generated Query: query='ReAct' filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='page', value=2) limit=None
# Search results
[Document(page_content='xxx', metadata={'page': 2, 'source': 'ReAct.pdf'})]The LLM successfully extracted the filter condition from the original question (filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='page', value=2)), and the result indeed comes from page 2.
Summary
Accurately retrieving documents from vector databases is crucial for building high-performance Retrieval-Augmented Generation (RAG) applications. The design of retrievers in LangChain follows an "abstract interface + concrete implementation" model, allowing for easy extension to different retrieval strategies to suit various use cases.
- VectorStoreRetriever is the most basic retriever, reusing the search methods of
VectorStore. It supports three search modes: semantic similarity (similarity), similarity threshold filtering (similarity_score_threshold), and Maximal Marginal Relevance (mmr). MMR not only considers document relevance but also ensures result diversity. - MultiQueryRetriever addresses the limitations of single-query searches by generating multiple queries from different perspectives. It uses an LLM to generate multiple questions, performs vector retrieval for each, and merges the results after deduplication.
- SelfQueryRetriever uses an LLM to extract potential metadata from the user's question as a filter, narrowing the search scope to improve speed and precision.