Appearance
Function Calling
"Offline" capability is a noticeable limitation of LLMs (Large Language Models). They can only respond based on the knowledge they were trained on and are unable to access real-time information or interact with external systems to retrieve data. For instance, if we ask, "What's the weather like in Beijing today?" the model might understand the intent behind the question, but since the training data cannot include real-time information, it can't provide an accurate response. It's like having a gun without bullets—quite frustrating.
Finally, in June 2023, OpenAI enabled function calling for its Chat Model, empowering LLMs with the ability to connect to external systems.
In the previous lesson, we learned about RunnableLambda, which also supports LLM interaction with external systems to some extent. However, whether or not it gets called is controlled by us during the creation of the LLM chain; the decision is already made. In contrast, OpenAI's function calling feature allows the model itself to decide whether a function needs to be called to accomplish the task.
Today, we'll dive into the basic concepts and interaction flow of function calling in OpenAI, and learn how LangChain integrates this functionality.
Interaction Principles of Function Calling
When hearing for the first time that LLMs support function calling, many may have a common misconception: that we can provide a pre-implemented function to the model, and it will execute the function directly when necessary. But it's not that magical. When we call the model, we provide it with the function signature and a description of the function's capabilities. The model then performs the following steps:
- Based on the user's input and the provided function description, the model decides whether a function call is necessary.
- If the function isn't needed, it will simply return the answer; if needed, it will extract information from the user's input, format it according to the required function parameters, and return the parameters.
In other words, we still execute the function ourselves; the model just tells us which function to execute and what the parameters are. Once we execute the function and obtain the result, we submit it back to the model, which then provides a coherent and accurate response.
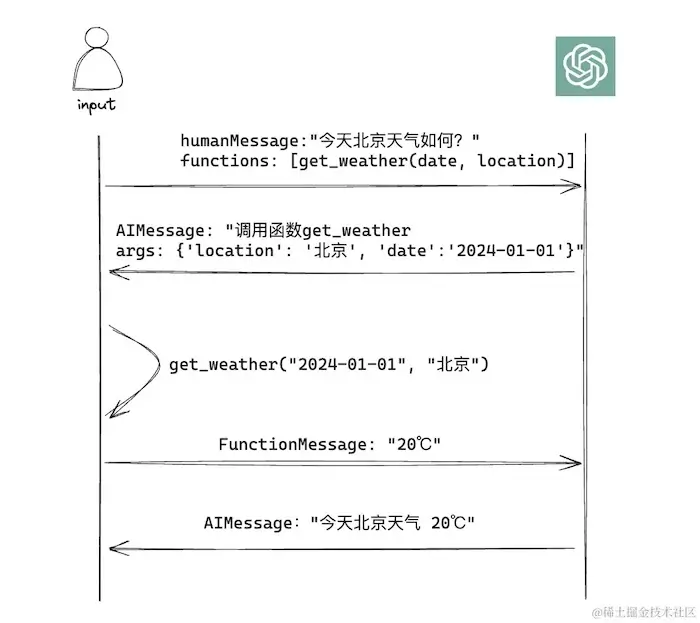
To distinguish between user messages and function call results, OpenAI introduced a function message type. When we return the result from a function call, it can be sent to the LLM as a function message.
Native OpenAI API Function Calls
OpenAI has a specific data structure designed for function calls. To better understand the interaction process, we will directly learn how to use OpenAI's native API.
OpenAI Native API Calls
Since the OpenAI native API hasn't been introduced before, let's briefly go over the basic usage of the OpenAI interface. As function calls only support the Chat Model, we will focus on how to call this chat model.
python
from openai import OpenAI
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'], base_url=os.environ['OPENAI_API_BASE'])
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a programming expert who answers user questions from a professional perspective."},
{"role": "user", "content": "Which programming language is the easiest?"}
]
)First, we create an OpenAI instance and specify the api_key and base_url during initialization, allowing even third-party proxy keys to be used.
The client.chat.completions.create method is used to call the model, with the model name and a list of messages as the main inputs. The message types are the same as previously introduced, including system, user, assistant, and function.
After calling the model, the response completion is as follows:
json
{
"id": "chatcmpl-93ICiWBkZZrpa08NLFt9LYttQLCj0",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "The easiest programming language to learn ...",
"role": "assistant",
"function_call": null,
"tool_calls": null
}
}
],
"created": 1710571988,
"model": "gpt-3.5-turbo-0613",
"object": "chat.completion",
"system_fingerprint": null,
"usage": {
"completion_tokens": 431,
"prompt_tokens": 41,
"total_tokens": 472
}
}Here, choices[0].message contains the model's response. The usage field represents the number of tokens used in this conversation, which is generally the basis for billing in LLM applications. For more information about the fields, refer to the official documentation.
Now that the basics of the OpenAI interface have been covered, let's proceed with the function call details.
Basic Process for OpenAI Function Calls
Define Business Functions
The first step is to define our business function. For instance, let's assume we have a function for retrieving the weather:
python
def get_weather(date, location):
print("After query, the weather in {} on {} is 20℃".format(location, date))
return "20℃"Create a List of Model Call Tools
The OpenAI.chat.completions.create method supports passing a list of tools. We can add the business function description as a JSON object to this tool list for the model to use during the call.
python
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the weather for a specified location on a specified date",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g., Beijing"
},
"date": {
"type": "string",
"description": "The date to get the weather, e.g., 2024-01-01"
}
},
"required": ["location", "date"]
}
}
}
]| Field Name | Description |
|---|---|
type | The type of tool. Currently, only "function" is supported. |
function | The description object for the business function. |
function.name | The business function name. |
function.description | Describes the function's purpose, which the model uses to determine when and how to call the function. |
function.parameters | The parameters accepted by the function. Leave this field empty if the function does not require any parameters. |
function.parameters.type | Fixed as "object". |
function.parameters.properties | The list of function parameters, where the key is each parameter's name and the value is the parameter's description object. The model extracts parameter values from user input based on the description. |
function.parameters.required | Specifies which parameters are mandatory when calling the function. |
Adding the Tool List to the Model Call
Now, we add the tools list to the OpenAI.chat.completions.create method to see the effect.
python
def get_weather(date, location):
print("After query, the weather in {} on {} is 20℃".format(location, date))
return "20℃"
tools = [{...}]
messages = []
messages.append({"role": "user", "content": "What's the weather like in Beijing on 2024-01-01?"})
completion = client.chat.completions.create(
model="gpt-3.5-turbo-0613",
messages=messages,
tools=tools
)
print(completion.choices[0].message)json
{
"content": null,
"role": "assistant",
"function_call": null,
"tool_calls": [
{
"ChatCompletionMessageToolCall": {
"id": "call_avmE2kG04Zu813cGCfkR6sSG",
"function": {
"arguments": "{\"location\": \"Beijing\", \"date\": \"2024-01-01\"}",
"name": "get_weather"
},
"type": "function"
}
}
]
}The model accurately deduced that calling a function is required to answer the user's question (message.tool_calls[0].type = "function"), and returned the function to be called (message.tool_calls[0].function.name = "get_weather") as well as the list of function arguments (message.tool_calls[0].function.arguments).
Manually Calling the Function
Next, we call the corresponding function based on the information returned by the model:
python
...
import json
llm_message = completion.choices[0].message
args = json.loads(llm_message.tool_calls[0].function.arguments)
location = args["location"]
date = args["date"]
temperature = get_weather(date, location)Passing the Function Result Back to the Model
Often, after calling the function, we need to pass the result back to the model for a more coherent response.
We can pass the function result to the model with the role set as "function". To ensure context continuity, the previous round's user message and the model's response should be included. The code is as follows:
python
...
# Add the model's previous response
messages.append(
{
"role": "assistant",
"function_call": {
"name": llm_message.tool_calls[0].function.name,
"arguments": llm_message.tool_calls[0].function.arguments
}
}
)
# Add the function result
messages.append({"role": "function", "name": "get_weather", "content": temperature})
# Call the model again
completion2 = client.chat.completions.create(
model="gpt-3.5-turbo-0613",
messages=messages,
tools=tools
)
print(completion2.choices[0].message)json
{
"content": "The weather in Beijing on January 1, 2024, is expected to be 20℃.",
"role": "assistant",
"function_call": null,
"tool_calls": null
}As seen, the model returns a semantic answer, and you can "fine-tune" the LLM's response tone or format according to specific scenario requirements to generate more satisfactory responses.
"Hallucinations" in Function Calls
Even when using function calls, models can experience "hallucinations." This means that while a model may correctly infer that a function call is needed to answer a user's question, it might "fill in" missing parameters by making incorrect assumptions if the provided information is incomplete. This could lead to incorrect results or even exceptions when calling the business function.
For example, in the earlier example, if we ask, "What's the weather like in 2024-01-01," leaving out the location, we can see how the model responds:
python
messages = []
messages.append({"role": "user", "content": "What's the weather like in 2024-01-01"})
completion = client.chat.completions.create(
model="gpt-3.5-turbo-0613",
messages=messages,
tools=tools
)
print(completion.choices[0].message)json
{
"content": null,
"role": "assistant",
"function_call": null,
"tool_calls": [
{
"id": "call_hmAeWUte4t9mqO3QzPGa1jq6",
"function": {
"arguments": "{\"location\": \"Beijing\", \"date\": \"2024-01-01\"}",
"name": "get_weather"
},
"type": "function"
}
]
}Here, the model "guessed" the location as "Beijing," which could cause the function to return incorrect results or throw an exception. To avoid this situation, prompt engineering can be used to add some constraints, instructing the model to request clarification when user input is incomplete.
python
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "What's the weather like in 2024-01-01"})
completion = client.chat.completions.create(
model="gpt-3.5-turbo-0613",
messages=messages,
tools=tools
)
print(completion.choices[0].message)json
{
"content": "Sure, I can help you with that. Can you please tell me the location for which you want to know the weather on January 1, 2024?",
"role": "assistant",
"function_call": null,
"tool_calls": null
}This time, the model did not "make assumptions" but instead asked the user to provide more information when encountering ambiguity.
Adding Location Information and Providing Context
Next, we add the location and include the previous conversation messages to give the model context:
python
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "What's the weather like in 2024-01-01"})
messages.append({"role": "assistant", "content": "I'm sorry, I didn't understand that. Can you please tell me the location for which you want to know the weather on January 1, 2024?"})
messages.append({"role": "user", "content": "Guangzhou"})
completion = client.chat.completions.create(
model="gpt-3.5-turbo-0613",
messages=messages,
tools=tools
)
print(completion.choices[0].message)json
{
"content": null,
"role": "assistant",
"function_call": null,
"tool_calls": [
{
"id": "call_lcHi4TUrV6jDgnCgEkw7lx69",
"function": {
"arguments": "{\"location\": \"Guangzhou\", \"date\": \"2024-01-01\"}",
"name": "get_weather"
},
"type": "function"
}
]
}After providing the location information, the model was able to infer the user's intent based on the context and returned the function call with the complete set of parameters.
Advanced Usage of Function Calls
Enforcing or Disabling Function Calls
The parameter tool_choice can be used to control whether or not a function call is made. For instance, we can force the model to use the get_weather function:
python
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "What's the weather like in 2024-01-01"})
completion = client.chat.completions.create(
model="gpt-3.5-turbo-0613",
messages=messages,
tools=tools,
# Forcing the use of the get_weather function
tool_choice={"type": "function", "function": {"name": "get_weather"}}
)
print(completion.choices[0].message)json
{
"content": null,
"role": "assistant",
"function_call": null,
"tool_calls": [
{
"id": "call_2KCnZVFRH3wIaC1ibPQnbgZu",
"function": {
"name": "get_weather",
"arguments": {
"location": "Beijing",
"date": "2024-01-01"
}
},
"type": "function"
}
]
}As shown above, even if the user's input is incomplete, the model still calls the get_weather function, and it may generate incorrect parameters.
When we want to prevent the model from using a function call, we can set tool_choice="none". Even if the question's intent is clear and all required information is provided, the model will not use function calls.
Parallel Function Calls
Some newer models (e.g., gpt-4-1106-preview or gpt-3.5-turbo-1106) support making multiple function calls in a single response. For example, if we want to inquire about the weather in Beijing on two different dates:
python
messages = []
messages.append({"role": "system", "content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."})
messages.append({"role": "user", "content": "What's the Beijing's weather like on 2024-01-01 and 2024-01-02?"})
completion = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=messages,
tools=tools
)
print(completion.choices[0].message)json
{
"content": null,
"role": "assistant",
"function_call": null,
"tool_calls": [
{
"id": "call_KJm4bnlpeh1Qwr7UibtQwoxQ",
"function": {
"name": "get_weather",
"arguments": {
"location": "Beijing",
"date": "2024-01-01"
}
},
"type": "function"
},
{
"id": "call_1RZFAWxvtEIDV9yRqsNv3mlU",
"function": {
"name": "get_weather",
"arguments": {
"location": "Beijing",
"date": "2024-01-02"
}
},
"type": "function"
}
]
}
}In the above output, the tool_calls array contains multiple elements, each representing an individual function call. The model made two calls to get_weather, each querying the weather for Beijing on a different date.
Handling the Results of Parallel Function Calls
After obtaining the results from the function calls, it is essential to pay attention to the order of the responses when adding messages for the next model call. The sequence should reflect the order of the function call messages and their corresponding results.
python
# Adding the model responses from the previous round
messages.append({
"role": "assistant",
"function_call":{
"name":"get_weather",
"arguments":"{\"location\": \"Beijing\", \"date\": \"2024-01-01\"}"
}
})
messages.append({
"role": "assistant",
"function_call":{
"name":"get_weather",
"arguments":"{\"location\": \"Beijing\", \"date\": \"2024-01-02\"}"
}
})
# Adding the function results in the same order
messages.append({"role": "function", "name": "get_weather", "content": "20℃"})
messages.append({"role": "function", "name": "get_weather", "content": "21℃"})
# Making another call to the model
...Maintaining the correct order of messages ensures that the model processes the context accurately, leading to coherent responses.
Function Calls in LangChain
In the above examples, constructing the function description object for business functions can be tedious. LangChain simplifies this process by using the pydantic library.
pydantic was briefly introduced in the "OutputParser: How to Control Model Output Format" section.
Creating Function Description with Pydantic Class
In LangChain, business functions are described by creating a subclass of BaseModel from pydantic, with each field specified using pydantic's Field to describe and constrain the fields.
python
from langchain_core.pydantic_v1 import BaseModel, Field
class GetWeather(BaseModel):
"""Get the weather for a specified location on a specified date"""
location: str = Field(description="The city and state, e.g. 北京")
date: str = Field(description="The date to get weather, e.g. 2024-01-01")In this code, the comment on the GetWeather class is necessary, as it will serve as the function's description.
Using the Pydantic Class for Function Description
Method 1: convert_pydantic_to_openai_function + JsonOutputFunctionsParser
LangChain provides the convert_pydantic_to_openai_function method to easily convert the above pydantic class into an OpenAI function description object.
python
from langchain_community.utils.openai_functions import (
convert_pydantic_to_openai_function
)
print(convert_pydantic_to_openai_function(GetWeather))Output:
json
{
"name": "GetWeather",
"description": "Get the weather for a specified location on a specified date",
"parameters": {
"type": "object",
"properties": {
"location": {
"description": "The city and state, e.g. 北京",
"type": "string"
},
"date": {
"description": "The date to get weather, e.g. 2024-01-01",
"type": "string"
}
},
"required": [
"location",
"date"
]
}
}Compared to manually constructing the description, convert_pydantic_to_openai_function generates the function description object conveniently, including the function name, description, parameter list, and required parameters.
After generating the function description, you can use the Runnable.bind method to pass the function description array into the functions parameter.
python
from langchain_openai import ChatOpenAI
chat = ChatOpenAI()
chat.bind(functions=[GetWeather])When the model predicts that a function call is needed, LangChain's JsonOutputFunctionsParser can easily parse the required function and related arguments.
python
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser
from langchain_openai import ChatOpenAI
from langchain_community.utils.openai_functions import (
convert_pydantic_to_openai_function
)
parser = JsonOutputFunctionsParser()
chain = ChatOpenAI().bind(functions=[convert_pydantic_to_openai_function(GetWeather)]) | parser
output = chain.invoke("What's the Beijing's weather like on 2024-01-01?")
print(output)Output:
json
{'location': '北京', 'date': '2024-01-01'}Method 2: bind_tools + JsonOutputToolsParser
In OpenAI, the concept of a tool has been defined, where function calls are one type of tool (currently, function calling is the only tool available). LangChain provides the Runnable.bind_tools method, allowing the direct use of the prepared pydantic class in one step!
python
from langchain_openai import ChatOpenAI
chat = ChatOpenAI().bind_tools([GetWeather])When parsing the function call information returned by the model with a chain built using the bind_tools-bound model instance, use the JsonOutputToolsParser provided by LangChain.
python
from langchain.output_parsers.openai_tools import JsonOutputToolsParser
from langchain_openai import ChatOpenAI
parser = JsonOutputToolsParser()
chain = ChatOpenAI().bind_tools([GetWeather]) | parser
output = chain.invoke("What's the Beijing's weather like on 2024-01-01?")
print(output)Output:
json
[{'type': 'GetWeather', 'args': {'location': '北京', 'date': '2024-01-01'}}]Summary
Function calls enable the model to integrate with other systems, leveraging its decision-making capabilities and overcoming the limitations of offline models. The model does not directly execute functions but rather suggests whether to call a function based on the user's query and the provided function description, returning detailed invocation information (such as the function name and parameters) to the application for execution.
While function calls may produce "hallucinations" when the user's input is incomplete, you can constrain this by using prompt techniques.
LangChain significantly simplifies the construction of function description objects and provides relevant output parsers for easily parsing model function call responses. Currently, more and more chat models (e.g., OpenAI, Gemini) support function call APIs.