Appearance
Document Segmentation
We will introduce how segmentation can provide efficiency and accuracy in RAG (Retrieval-Augmented Generation) applications from several angles: why segmentation is needed, what segmentation strategies exist, and how to choose a strategy for segmentation.
Why Segmentation is Necessary
Document segmentation refers to the process of dividing loaded documents into smaller chunks.
In the previous lesson, we actually encountered this, such as how PyPDFLoader loads the entire data into multiple document chunks by page; the elements mode of UnstructuredFileLoader, which chunks the entire data by elements.
Let's review the entire RAG process. If we do not consider document segmentation, the loaded documents will first be vectorized using an embedding model, stored in a vector database, and then retrieved to be submitted along with the user's question to the LLM (Large Language Model). From this perspective, the process seems straightforward. So, why is chunking still necessary?
Document Embedding
Document vectorization involves extracting data features, compressing and reducing dimensions, and converting them into a set of numerical arrays or matrices in vector form. The larger the document, the more information is lost after vectorization, which can severely impact subsequent retrieval effectiveness. Additionally, different embedding models perform with varying efficiency on different sizes of document chunks. For instance, sentence embedding models perform better when handling individual sentences, while OpenAI's text-embedding-ada-002 embedding model performs better on chunks sized at 256 or 512 tokens.
Storing in Vector Databases
The dimensional values of vectorized large document chunks will generally be higher than those of smaller chunks, posing a challenge for vector databases. This increases storage space and computational resource requirements while reducing data retrieval performance and efficiency.
Retrieval
When retrieving document data based on user questions, if a single document is too large, the relevance of the retrieval results will be lower. For example, a 1000-word document may only briefly mention programming in 50 words. If the user inputs a question related to programming, the entire large document may be returned, which reduces the relevance of the document. The relevance of the document directly affects the accuracy of the output results from the LLM.
LLM Invocation
Currently, LLM models have limitations on the number of tokens that can be sent in a single request. The entire document data may exceed the model's limits. However, as LLMs evolve, these limitations will likely diminish. For example, the domestic large model Kimi has recently been released and can now support 2 million Chinese characters in context, which is about 32 times that of GPT-4 Turbo!
Thus, document segmentation is essential when building RAG applications. The goal of segmentation is to ensure that the data chunks are small enough while maintaining the semantic relevance of the document chunks.
These two objectives can be contradictory. If the chunks are too small, it may lead to the loss of contextual information, resulting in incomplete semantics of the document chunks. For instance: “Xiaoming likes Xiaohong, and he also likes Xiaoqing.” If this document is divided into two chunks: “Xiaoming likes Xiaohong” and “he also likes Xiaoqing,” when asked the question, “Who does Xiaoming like?”, only “Xiaoming likes Xiaohong” can be retrieved, losing the information about his other love, “Xiaoqing.”
Therefore, document segmentation needs to be considered with trade-offs based on the application scenario. LangChain provides a series of document segmentation methods for us to choose from. Below, we will explain some common strategies in detail.
Common Segmentation Strategies in LangChain
The segmenters in LangChain are located in the langchain_text_splitters library, which we need to install manually:
bash
pip install langchain_text_splittersMost document segmenters inherit from TextSplitter. Let's take a look at some key parts of the TextSplitter code:
python
class TextSplitter(BaseDocumentTransformer, ABC):
# Initialize the splitter
def __init__(
self,
# Size of each document chunk after segmentation
chunk_size: int = 4000,
# Number of overlapping characters between two segments
chunk_overlap: int = 200,
...
) -> None:
@abstractmethod
def split_text(self, text: str) -> List[str]:
"""Split text into multiple components."""
# Split multiple texts into a list of documents based on a strategy
def create_documents(
self, texts: List[str], metadatas: Optional[List[dict]] = None
) -> List[Document]:
_metadatas = metadatas or [{}] * len(texts)
documents = []
for i, text in enumerate(texts):
...
# Call split_text to divide large texts into smaller texts
for chunk in self.split_text(text):
metadata = copy.deepcopy(_metadatas[i])
...
# Wrap into document objects
new_doc = Document(page_content=chunk, metadata=metadata)
documents.append(new_doc)
return documents
# Split multiple documents into multiple document lists based on a strategy
def split_documents(self, documents: Iterable[Document]) -> List[Document]:
texts, metadatas = [], []
for doc in documents:
texts.append(doc.page_content)
metadatas.append(doc.metadata)
return self.create_documents(texts, metadatas=metadatas)
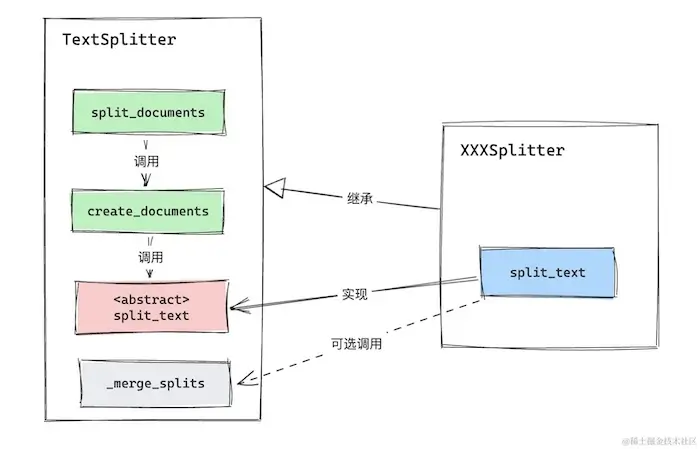
def _merge_splits(self, splits: Iterable[str], separator: str) -> List[str]:create_documents and split_documents are two methods we frequently use in actual development, both of which can create a list of documents. The split_documents method first retrieves the text content (page_content) and metadata from the passed documents, then calls create_documents for re-segmentation.
The create_documents method ultimately calls split_text for segmentation. The TextSplitter itself does not implement split_text; individual document segmenters must implement the segmentation logic according to their own strategies.
Next, let’s look at the two parameters passed when initializing TextSplitter: chunk_size and chunk_overlap.
- chunk_size: Limits the size of each document chunk after segmentation.
- chunk_overlap: Maximum number of overlapping characters between two document chunks.
chunk_overlap ensures the coherence and completeness of document chunk semantics. Taking the previous example document, “Xiaoming likes Xiaohong, and he also likes Xiaoqing,” if we segment it into two document chunks: “Xiaoming likes Xiaohong” and “he also likes Xiaoqing,” and set chunk_overlap > 0, the two documents may be merged back into one: “Xiaoming likes Xiaohong, and he also likes Xiaoqing.” This way, the semantic integrity of the document is preserved.
The merging method is provided by TextSplitter through _merge_splits. This method attempts to merge the provided text list based on chunk_size and chunk_overlap according to the following rules:
- If a document chunk >
chunk_size, do not merge. - If
chunk_overlap < Document chunk < chunk_size:- If Document chunk + subsequent document chunk >
chunk_size, do not merge.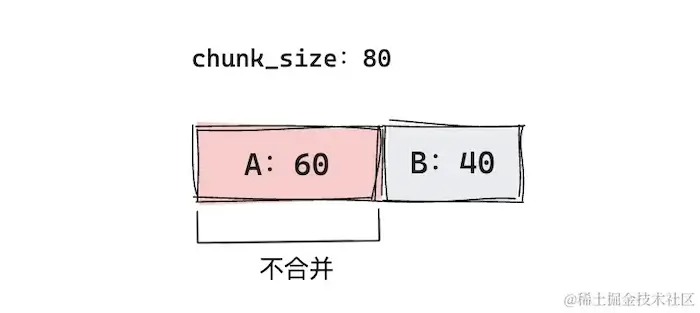
- If Document chunk + subsequent document chunk <=
chunk_size, merge.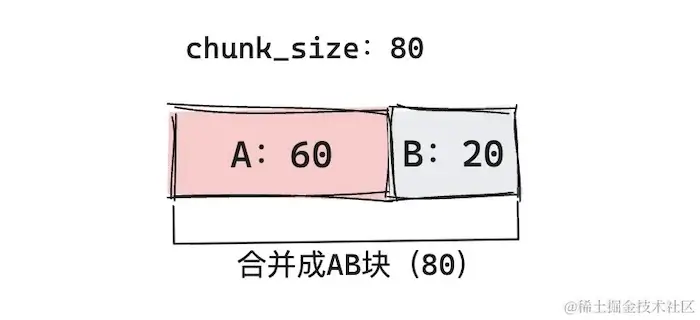
- If Document chunk + subsequent document chunk >
- If Document chunk <
chunk_overlap:- If adjacent document + Document chunk >
chunk_size, do not merge.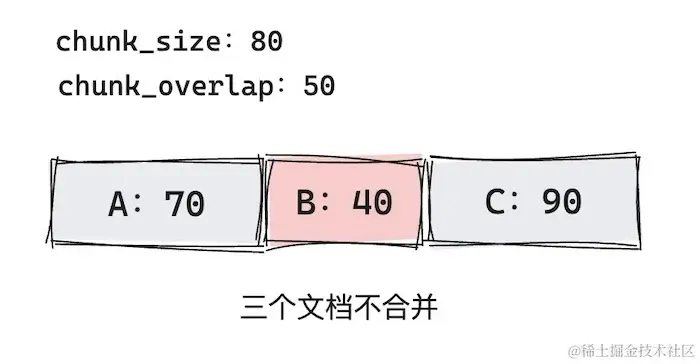
- If previous document + Document chunk <=
chunk_size, merge with the previous document.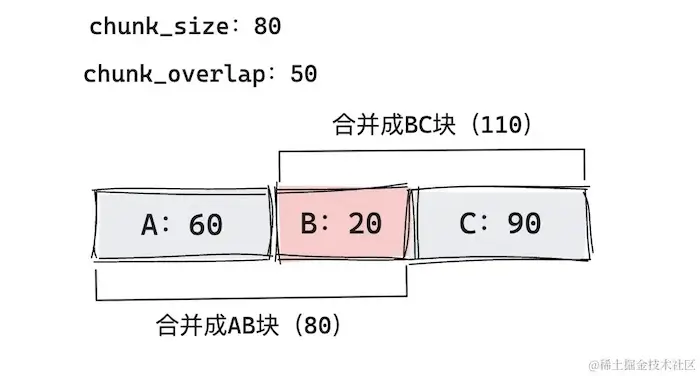
- If adjacent document + Document chunk >
From the illustration above, we can see that _merge_splits can merge smaller documents (usually split by a specific delimiter) into documents that do not exceed chunk_size as much as possible (there may still be special cases that exceed chunk_size, as seen in the last image where BC chunk exceeds the limit).
At the same time, particularly small documents (less than chunk_overlap) may also be merged with adjacent documents, allowing for some overlap and maintaining semantic continuity.
It is important to note that _merge_splits takes into account the length of the delimiter when merging. Assuming the delimiter in the illustration is "\n\n", if document chunk A has a length of 60, which includes a 2-character delimiter, then the actual content length is only 58.
_merge_splits is optional; each segmenter can choose whether to call it in the split_text method based on their needs.
With that, we have introduced the basic principles and architecture of TextSplitter in LangChain. Next, we will explore several common document segmenters in LangChain, from simple to complex.
Character Text Segmentation
Character-based segmentation is the simplest segmentation strategy, where we specify a delimiter and split the text according to that delimiter. In LangChain, this segmentation strategy is implemented by the CharTextSplitter.
python
class CharTextSplitter(TextSplitter):
def __init__(
self,
...
# Specify the delimiter
separator: str = "\n\n",
) -> None:
def split_text(self, text: str) -> List[str]:
# Get the delimiter
separator = (
self._separator if self._is_separator_regex else re.escape(self._separator)
)
# Split the text by the delimiter
splits = _split_text_with_regex(text, separator, self._keep_separator)
_separator = "" if self._keep_separator else self._separator
# Call TextSplitter._merge_splits to merge the split text
return self._merge_splits(splits, _separator)CharTextSplitter defaults to splitting by double line breaks \n\n. Let’s look at a specific example. To prevent _merge_splits from merging documents, we set chunk_size and chunk_overlap to very small values.
python
from langchain_text_splitters import CharacterTextSplitter
splitter = CharacterTextSplitter(
chunk_size=1,
chunk_overlap=0
)
text = '666666\n\n333\n\n22'
print(splitter.split_text(text))
"""
['666666', '333', '22']
"""Sentence Segmentation
As mentioned earlier, some embedding models are specifically optimized for individual sentence embeddings. Therefore, in some cases, we may want to split data by sentences.
NLTK and spaCy are two popular natural language processing libraries in Python, both of which provide rich tools and functionalities for analyzing and processing text data. LangChain leverages these two libraries to design NLTKTextSplitter and SpacyTextSplitter.
NLTKTextSplitter
NLTK is one of the earliest NLP libraries in Python and offers tools for various language processing tasks, including tokenization, part-of-speech tagging, named entity recognition, and parsing. LangChain uses the sentence tokenizer from the NLTK library to implement text segmentation by sentences.
python
class NLTKTextSplitter(TextSplitter):
"""Splitting text using NLTK package."""
def __init__(
self, separator: str = "\n\n", language: str = "english", **kwargs: Any
) -> None:
...
from nltk.tokenize import sent_tokenize
self._tokenizer = sent_tokenize
...
self._separator = separator
self._language = language
def split_text(self, text: str) -> List[str]:
"""Split incoming text and return chunks."""
# Use the tokenizer to split sentences
splits = self._tokenizer(text, language=self._language)
# Call TextSplitter._merge_splits to merge the split sentences
return self._merge_splits(splits, self._separator)NLTKTextSplitter also calls TextSplitter._merge_splits to merge after splitting sentences.
python
from langchain_text_splitters import NLTKTextSplitter
splitter = NLTKTextSplitter(
chunk_size=1,
chunk_overlap=0
)
text = 'This is a test sentence for testing NLTKTextSplitter! It will be splitted to several sub sentences, let see how it works.'
print(splitter.split_text(text))
"""
['This is a test sentence for testing NLTKTextSplitter!', 'It will be splitted to several sub sentences, let see how it works.']
"""As we can see, NLTKTextSplitter can automatically differentiate between different punctuation marks and will split sentences when encountering terminal punctuation (such as question marks, periods, exclamation marks, etc.).
SpacyTextSplitter
NLTK can be slower when processing large texts, as it is more geared towards educational scenarios.
spaCy is a Python library developed using C++, which is faster and optimized for production environments. It uses newer algorithms and pre-trained models to provide higher accuracy in segmentation, along with effective parallel processing and better memory management solutions, making it suitable for handling large datasets.
Before using SpacyTextSplitter, we need to install the spaCy library and the required models in advance. SpacyTextSplitter defaults to using the en_core_web_sm model. Below is how to install the model in a normal Python environment and when managing the project with pdm:
Normal Python Environment:
bash
python -m spacy download en_core_web_smUsing PDM:
bash
pdm add https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.7.1/en_core_web_sm-3.7.1.tar.gzThe above URL can be replaced with the actual version number of the model needed. You can find the correct version number and download link on the official spaCy model release page.
After downloading the model, using SpacyTextSplitter is straightforward:
python
from langchain_text_splitters import SpacyTextSplitter
splitter = SpacyTextSplitter(
chunk_size=1,
chunk_overlap=0
)
text = 'This is a test sentence for testing NLTKTextSplitter! It will be splitted to several sub sentences, let see how it works.'
print(splitter.split_text(text))
"""
['This is a test sentence for testing NLTKTextSplitter!', 'It will be splitted to several sub sentences, let see how it works.']
"""Recursive Character Text Segmentation
The problem with CharTextSplitter is that it only specifies a single delimiter, which may result in document chunks that are significantly larger than the intended chunk_size. The RecursiveCharacterTextSplitter effectively addresses this issue by allowing us to specify a set of delimiters. After initially splitting the document with the first delimiter, if the resulting chunks do not meet the expected size, it recursively applies the remaining delimiters until the document chunks reach the desired size or all delimiters have been tried.
The default delimiter list for RecursiveCharacterTextSplitter is ["\n\n", "\n", " ", ""].
Here is an example of using RecursiveCharacterTextSplitter:
python
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=5,
chunk_overlap=1
)
# The following text is a test for the RecursiveCharacterTextSplitter
text = "This is a test text for the RecursiveCharacterTextSplitter. It is a long text with many words."
print(splitter.split_text(text))
"""
['This', 'is a', 'test', 'text', 'for', 'the', 'Recu', 'ursiv', 'veCha', 'aract', 'terTe', 'extSp', 'plitt', 'ter.', 'It', 'is a', 'long', 'text', 'with', 'many', 'word', 'ds.']
"""As we can see, the default delimiter "" ensures that we can generate document chunks of the desired size. However, it may lead to chunks that lack clear semantics, so we need to decide whether to use this based on the specific context.
The ability of RecursiveCharacterTextSplitter to recursively split documents with multiple delimiters grants it a wide range of applications, including the ability to split code files from various programming languages.
LangChain provides a list of supported languages for splitting in langchain_text_splitters.Language.
python
from langchain_text_splitters import Language
print([e.value for e in Language])
"""
['cpp', 'go', 'java', 'kotlin', 'js', 'ts', 'php', 'proto', 'python', 'rst', 'ruby', 'rust', 'scala', 'swift', 'markdown', 'latex', 'html', 'sol', 'csharp', 'cobol', 'c', 'lua', 'perl']
"""LangChain has predefined different delimiter lists for various languages.
python
from langchain_text_splitters import (
Language,
RecursiveCharacterTextSplitter,
)
print(RecursiveCharacterTextSplitter.get_separators_for_language(Language.PYTHON))
"""
['\nclass ', '\ndef ', '\n\tdef ', '\n\n', '\n', ' ', '']
"""We can create a language-specific splitter using RecursiveCharacterTextSplitter.from_language, which retrieves the corresponding delimiter list for the specified language and instantiates a RecursiveCharacterTextSplitter object.
python
class RecursiveCharacterTextSplitter(TextSplitter):
@classmethod
def from_language(
cls, language: Language, **kwargs: Any
) -> RecursiveCharacterTextSplitter:
separators = cls.get_separators_for_language(language)
return cls(separators=separators, is_separator_regex=True, **kwargs)Let’s look at the segmentation effect for Python code:
python
from langchain_text_splitters import Language, RecursiveCharacterTextSplitter
code = """
def hello_world():
print("Hello World!")
if __name__ == '__main__':
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
python_chunks = python_splitter.split_text(code)
print(python_chunks)
"""
['def hello_world():\n print("Hello World!")', "if __name__ == '__main__':\n hello_world()"]
"""This example demonstrates how RecursiveCharacterTextSplitter effectively splits Python code into manageable chunks while respecting the syntax of the language.
Semantic Segmentation
The splitting strategies mentioned above have a notable drawback: they do not consider the semantic completeness and coherence of the text. While NLTKTextSplitter and SpacyTextSplitter can accurately segment documents into sentences, they do so without regard to semantic relationships. For example, consider the text: "Xiao Ming likes Xiao Hong. He also likes Xiao Qing." Both NLTKTextSplitter and SpacyTextSplitter will split this into two document chunks due to the period, despite the strong semantic connection between them. Treating these as a single document chunk would be more reasonable.
Other splitting strategies simply divide the text based on predetermined delimiters, which further exacerbates this issue.
SemanticChunker
Is there a method that can group semantically related content together as a single document chunk? LangChain has implemented SemanticChunker, which first segments the entire text into sentences. It then uses an embedding model to compute the vector values of each sentence, comparing the cosine distances between adjacent sentences to determine their semantic similarity and decide whether to merge them.
Sentence Segmentation
In SemanticChunker, the input text is segmented using the delimiters '.', '?', and '!'.
It's important to note that this implementation does not consider Chinese punctuation marks. Therefore, special attention must be given to modifying these delimiters when processing Chinese text.
python
class SemanticChunker(BaseDocumentTransformer):
def split_text(
self,
text: str,
) -> List[str]:
# Splitting the essay on '.', '?', and '!'
single_sentences_list = re.split(r"(?<=[.?!])\s+", text)
...Initial Sentence Merging
SemanticChunker merges adjacent sentences to maintain continuity, similar to the chunk_overlap discussed earlier. It uses a configurable parameter called buffer_size for this purpose, with a default value of 1. For example, after the first step of segmentation resulting in chunks A, B, C, and D, a buffer_size of 1 will merge them into AB, ABC, BCD, and CD. In other words, each sentence chunk is combined with the preceding and succeeding sentence blocks based on the buffer_size.
python
def combine_sentences(sentences: List[dict], buffer_size: int = 1) -> List[dict]:
for i in range(len(sentences)):
combined_sentence = ""
for j in range(i - buffer_size, i):
if j >= 0:
combined_sentence += sentences[j]["sentence"] + " "
combined_sentence += sentences[i]["sentence"]
for j in range(i + 1, i + 1 + buffer_size):
if j < len(sentences):
combined_sentence += " " + sentences[j]["sentence"]
sentences[i]["combined_sentence"] = combined_sentence
return sentencesCalculating Sentence Embeddings
Next, the embeddings for each chunk are computed:
python
embeddings = self.embeddings.embed_documents(
[x["combined_sentence"] for x in sentences]
)
for i, sentence in enumerate(sentences):
sentence["combined_sentence_embedding"] = embeddings[i]Calculating Cosine Distances
The cosine distance between each chunk and the next is calculated and recorded:
python
def calculate_cosine_distances(sentences: List[dict]) -> Tuple[List[float], List[dict]]:
"""Calculate cosine distances between sentences."""
distances = []
for i in range(len(sentences) - 1):
embedding_current = sentences[i]["combined_sentence_embedding"]
embedding_next = sentences[i + 1]["combined_sentence_embedding"]
similarity = cosine_similarity([embedding_current], [embedding_next])[0][0]
distance = 1 - similarity
distances.append(distance)
sentences[i]["distance_to_next"] = distance
return distances, sentencesNow we have an array of cosine distances between the chunks.
python
print(distances)
"""
[0.08081114249044896, 0.02726339916925502, 0.04722227403602797]
"""Visualizing this data can provide clearer insights into the relationships:
[Graph taken from the implementation article]
Setting Breakpoints
A larger cosine distance indicates that the document chunks are semantically less related. We can set a threshold value to traverse through the sentence chunks, merging them as long as the cosine distance to the next sentence is below the threshold, until it exceeds this limit.
[Graph taken from the implementation article]
Threshold Calculation
SemanticChunker currently supports three methods for calculating breakpoints: Percentile, Standard Deviation, and Interquartile.
python
BREAKPOINT_DEFAULTS: Dict[BreakpointThresholdType, float] = {
"percentile": 95,
"standard_deviation": 3,
"interquartile": 1.5,
}python
class SemanticChunker(BaseDocumentTransformer):
def __init__(
...
breakpoint_threshold_type: BreakpointThresholdType = "percentile",
breakpoint_threshold_amount: Optional[float] = None,
...
):
self.breakpoint_threshold_type = breakpoint_threshold_type
if breakpoint_threshold_amount is None:
self.breakpoint_threshold_amount = BREAKPOINT_DEFAULTS[
breakpoint_threshold_type
]
else:
self.breakpoint_threshold_amount = breakpoint_threshold_amount
# Calculate breakpoint threshold
def _calculate_breakpoint_threshold(self, distances: List[float]) -> float:
if self.breakpoint_threshold_type == "percentile":
return cast(
float,
np.percentile(distances, self.breakpoint_threshold_amount),
)
elif self.breakpoint_threshold_type == "standard_deviation":
return cast(
float,
np.mean(distances)
+ self.breakpoint_threshold_amount * np.std(distances),
)
elif self.breakpoint_threshold_type == "interquartile":
q1, q3 = np.percentile(distances, [25, 75])
iqr = q3 - q1
return np.mean(distances) + self.breakpoint_threshold_amount * iqrThe default calculation method for SemanticChunker is Percentile. You can adjust this during initialization by modifying breakpoint_threshold_type.
Each calculation method has a coefficient, breakpoint_threshold_amount, which affects the final threshold value. Here’s a brief explanation of each method:
Percentile: Represents the proportion of observations that fall below a certain value. For example, the 50th percentile (median) indicates that half the observations are below this value. By default, the percentile threshold is set to 95, meaning the threshold is determined by the 95th percentile.
Standard Deviation: Measures the degree of deviation of values in a dataset from the mean. A higher standard deviation indicates a wider distribution of data, while a lower standard deviation indicates a more concentrated distribution. The threshold is calculated as the mean plus the product of the standard deviation and the
breakpoint_threshold_amount.Interquartile: Divides a dataset into four equal parts, determined by three points (25th percentile ( q1 ), 50th percentile ( q2 ), and 75th percentile ( q3 )). The Interquartile Range (IQR) is the difference between ( q3 ) and ( q1 ), which describes the distribution range of the central 50% of the data. In
SemanticChunker, the IQR is multiplied bybreakpoint_threshold_amountand added to the mean to yield an adjusted weighted average.
Practical Example
It's important to note that the effectiveness of this semantic segmentation has not been extensively validated in practical scenarios. Therefore, LangChain currently includes SemanticChunker in the langchain_experimental package.
Let’s demonstrate the effectiveness of SemanticChunker using a segment from the LangChain official website:
python
text = """
LangChain is a framework for developing applications powered by language models. It enables applications that:
Are context-aware: connect a language model to sources of context (prompt instructions, few shot examples, content to ground its response in, etc.)
Reason: rely on a language model to reason (about how to answer based on provided context, what actions to take, etc.)
This framework consists of several parts.
LangChain Libraries: The Python and JavaScript libraries. Contains interfaces and integrations for a myriad of components, a basic run time for combining these components into chains and agents, and off-the-shelf implementations of chains and agents.
LangChain Templates: A collection of easily deployable reference architectures for a wide variety of tasks.
LangServe: A library for deploying LangChain chains as a REST API.
LangSmith: A developer platform that lets you debug, test, evaluate, and monitor chains built on any LLM framework and seamlessly integrates with LangChain.
"""
from langchain_openai import OpenAIEmbeddings
text_splitter = SemanticChunker(embeddings=OpenAIEmbeddings())
chunks = text_splitter.split_text(text)
print(len(chunks)) # 2
print(chunks)
"""
['\nLangChain is a framework for developing applications powered by language models. It enables applications that:\n\nAre context-aware: connect a language model to sources of context (prompt instructions, few shot examples, content to ground its response in, etc.)\nReason: rely on a language model to reason (about how to answer based on provided context, what actions to take, etc.)\nThis framework consists of several parts. LangChain Libraries: The Python and JavaScript libraries.',
'Contains interfaces and integrations for a myriad of components, a basic run time for combining these components into chains and agents, and off-the-shelf implementations of
chains and agents. LangChain Templates: A collection of easily deployable reference architectures for a wide variety of tasks. LangServe: A library for deploying LangChain chains as a REST API. LangSmith: A developer platform that lets you debug, test, evaluate, and monitor chains built on any LLM framework and seamlessly integrates with LangChain. ']
"""By adjusting the breakpoint_threshold_type and breakpoint_threshold_amount during initialization, you can achieve different results.
Considerations for Splitting Strategies
There is no one-size-fits-all solution for splitting strategies; different strategies are suitable for various scenarios. It’s crucial to choose the appropriate strategy based on your specific business context. When considering splitting strategies, several aspects should be evaluated. Here are some key points to keep in mind:
What is the type of content in the original document? Is it a book, an article, or a chat message?
What embedding model is being used? Different models perform differently based on the size of the document chunks.
What characteristics do the expected user queries have? Are they simple short phrases or complex long sentences?
What are the token limitations of the LLM model being used? What is the performance like under different token counts?
Addressing these questions can help us balance performance and accuracy in selecting an appropriate splitting strategy. It’s important to note that determining a splitting strategy is also an iterative process that requires continuous adjustments and testing to achieve the desired results.
Conclusion
In LangChain, document splitting is a critical step that influences the retrieval efficiency and accuracy of RAG applications. By employing a suitable splitting strategy, we can maintain the semantic relevance of document chunks while ensuring they remain sufficiently small, thus enhancing overall application performance.
Today, we discussed several common splitters implemented in LangChain. It’s essential not only to understand how to use them but also to comprehend their underlying principles. This understanding will provide greater confidence when choosing or developing our own document splitters.
Formulating a splitting strategy requires a comprehensive consideration of various factors, including the characteristics of the document content, the embedding model being used, user query habits, and the limitations of the LLM model. This ensures that the final chosen strategy meets the application's needs. Additionally, the selection and adjustment of document splitting strategies are iterative processes that necessitate ongoing testing and optimization to achieve the best results.